
Recently, I was asked to return to speak at the CarMax/Edmunds DevOps Days 2023 event. Rather than asking about a specific topic, the organizers graciously asked me (paraphrasing) to prepare “whatever was currently on my mind”. Like a lot of folks, AI has been something I’ve not only heard a lot about, but spent time working with. In this presentation, I share some of my current thinking.

Hello, everyone. My name is Matthew Reinbold, and I am a software strategy consultant with a couple of decades of enterprise integration experience to call on. I’m passionate about creating better software – you might remember me from the presentation that I gave last year, Seven Skills to Change Complex Software Systems. I’m delighted to have been asked back to present what’s been on my mind this past year.
I’m the guy behind Net API Notes, an API industry newsletter I’ve authored since 2015. In that time, I’ve seen various tools, techniques, and trends come and go. However, regarding today’s discussions about AI, I don’t know if I have seen anything as simultaneously under and overhyped.
In the time that we have here today, I’ll:
- Highlight opportunities where Large Language Models (or LLMs) can enhance everyday tasks
- Shine a light on how to use the tools better for API design and development
- Draw some distinct boundaries where LLM users - API creators or not - should continue to be careful

I must stress that LLMs aren’t just something that happened in the last few years. I led the Capital One API Center of Excellence for over a half-decade. Because of my team’s success with APIs, we were asked to contribute to later data transformation and event-streaming initiatives, creating the operational backbone and digital capabilities necessary for LLMs execution.
An increasing amount of my API work in recent years has explored what it means to use powerful natural language models in software environments:
- Why AI Success is API Built (2020)
- Machine Learning Prompts Within IDEs (2021)
- A Road Map for AI Governance (2019)
- What Happened When Github’s AI Copilot Wrote My OpenAPI Description (2022)
- The Thing About Using ChatGPT for API Design (2022)
- What Quantifying Good API Design, Even With AI, Is Not the Homerun Metric You Think It Is
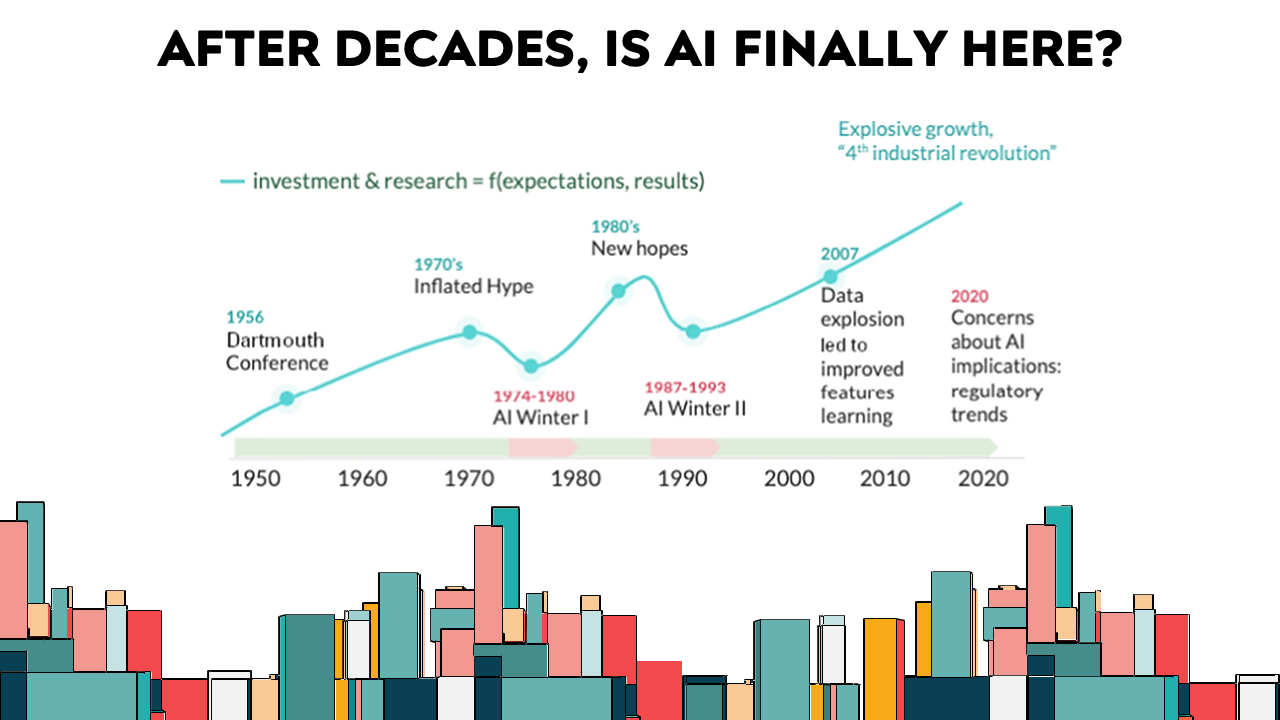
There’s a challenge in covering such a fast-moving topic. Those familiar with the long history of AI will readily acknowledge that it goes through periods of boom and bust. Initial excitement at sprouting new approaches quickly melts under the bright lights of reality. Much of the 80s and 90s was dominated by times of under-investment, referred to as ‘AI winters’.
It seemed like we reached something a plateau in 2019 or 2020, after an especially intense period of excitement around new LLM methods. However, the rapid release of AI tools in recent years – tools like Dalle-2, Midjourney, Stable Diffusion, and ChatGPT, has poured gasoline on an already brightly burning fire. In fact, ChatGPT recently set a record for the fastest-growing user base in history.
As tool users and creators, evaluating the impact of these developments is part of our jobs. My field of expertise is APIs, so for much of this presentation, I’ll try to answer how LLMs can supplement and create better APIs.
[Image taken from “The winter, the summer, and the summer dream of artificial intelligence in law” paper by Enrico Francesconi]

Before we can start talking about how today’s current crop of Large Language Models (or LLMs) can help you in your API creation, I first need to make sure that we’re all on the same page about what we’re talking about, because, like so many extremely popular things, there have been lots said. Terms have been distorted to support people’s preferred or self-serving narratives, causing confusion for general comprehension.
For the rest of the presentation, I will try and avoid using the term ‘artificial intelligence’ or AI. The term is incredibly overloaded, almost to the point of meaninglessness. Further, when many of us hear “AI”, we’re actually thinking about “Artificial GENERAL Intelligence”, or the kind of self-aware conscious construct we see in sci-fi movies and read about in futuristic books. The current crop of LLMs is not that – in fact, they are very far from it. However, some of the biggest names in the space are working hard to present that very impression.
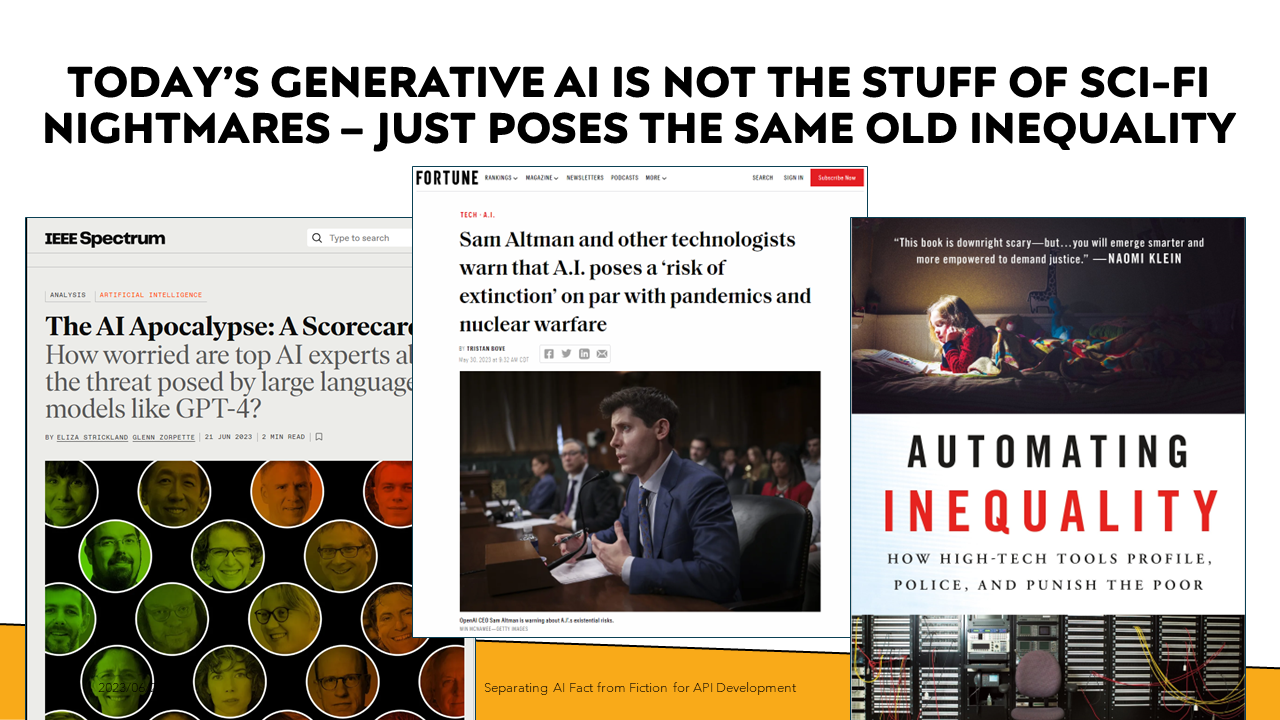
Sam Altman, CEO of OpenAI, creators of ChatGPT and image generation Dalle-2, has warned that AI poses ‘risk of extinction’ to humanity, on par with pandemics and nuclear warfare.
At the same time, an open letter has been circulated, signed by several prominent figures, calling for a temporary halt to LLM training and development so the potential risks can be studied. That sounds like a reasonable request until you dig deeper into what is being asked for. Those concerns are not about paying the creators whose work was used to train the model. They are not about mitigating existing injustice. Rather, the risks were imagined ‘AI Apocalypses’.
As scientist, author, and current AI-hype critic Emily Bender points out:
“Powerful corporations hype about LLMs and their progress toward AGI create a narrative that distracts from the need for regulations that protect people from these corporations.”
There is a certain amount of hubris in going before the world’s governments and declaring that “we’re so good at our jobs, you must acknowledge us”. Especially when at the same time, you’re marketing your products as “too good”, you undermine good faith efforts to regulate AI.
I’ve spent a decent amount of my career in software governance. I know what regulatory capture looks like. Or in other words, this is a deliberate attempt to maintain the status quo of existing leaders while creating onerous burdens on those attempting to enter the space. And there’s reasons for AI incumbents to be concerned.
The danger with automation isn’t some remote, far-off sci-fi dystopia. Instead, the harms are the much more mundane, everyday negligence that Virginia Eubanks documented in her 2018 book, Automating Inequality. Software can perpetuate bad systems. Automation can perpetuate bad systems at scale.

If today’s generative AI isn’t a pending AI Apocalypse, then what is it?
People are incredibly creative in imagining human-like properties in the things we interact with. People using a simple program in the 1960s named Eliza believed they were having a conversation with a live human being. People see pictures of Jesus in a Dorito. As a species, we’re good at projecting human qualities in the things surrounding us. However, that creativity causes problems when we try to get at what LLMs are good at. Saying that LLMs are “creating” or “hallucinating”, anthropomorphizes the technology and muddies our understanding how to be productive with it.
Explaining the mathematical basis of how these systems work is outside the scope of this presentation. However, one helpful way of thinking about LLMs is as “word calculators”. Or, as the title of the slide says, the way that LLM’s statistical probability routines work is that a model will try and complete a document in the most statistically likely way possible. It is not trying to be correct. It is trying to complete a document.
One way to illustrate this is shown in the slide. “Which is heavier, one pound of feathers or one pound of lead” is a common introductory science question for exploring mass, density, and weight concepts. In its training, ChatGPT ingested copious amounts of text where the answer appearing after the question was “a pound of feathers and a pound of lead weigh the same amount”.
When I slightly tweak the question and ask what is heavier, “a pound of feathers or five pounds of lead” ChatGPT isn’t parsing the sentence and applying logic the way we do. Rather, it is attempting to answer the question in the most statistically probable way – since it has seen that similar questions often result in “they’re the same”, it too replies that the weights are the same. Amusingly, it then goes on to contradict itself in the next sentence.
An essential part of successfully working with an LLM, like ChatGPT, is following an iterative process that allows us to surface and correct these internal assumptions. It is less about creating the perfect, singular prompt to perform work – asking ChatGPT to “Write an application that will make me rich” will end in disappointment. Instead, it is about thinking critically and creatively about refining what we’re after.

We’re almost to the point where we’re about to play with some responses. However, let’s cover some final important warnings if you use something like ChatGPT for business use.
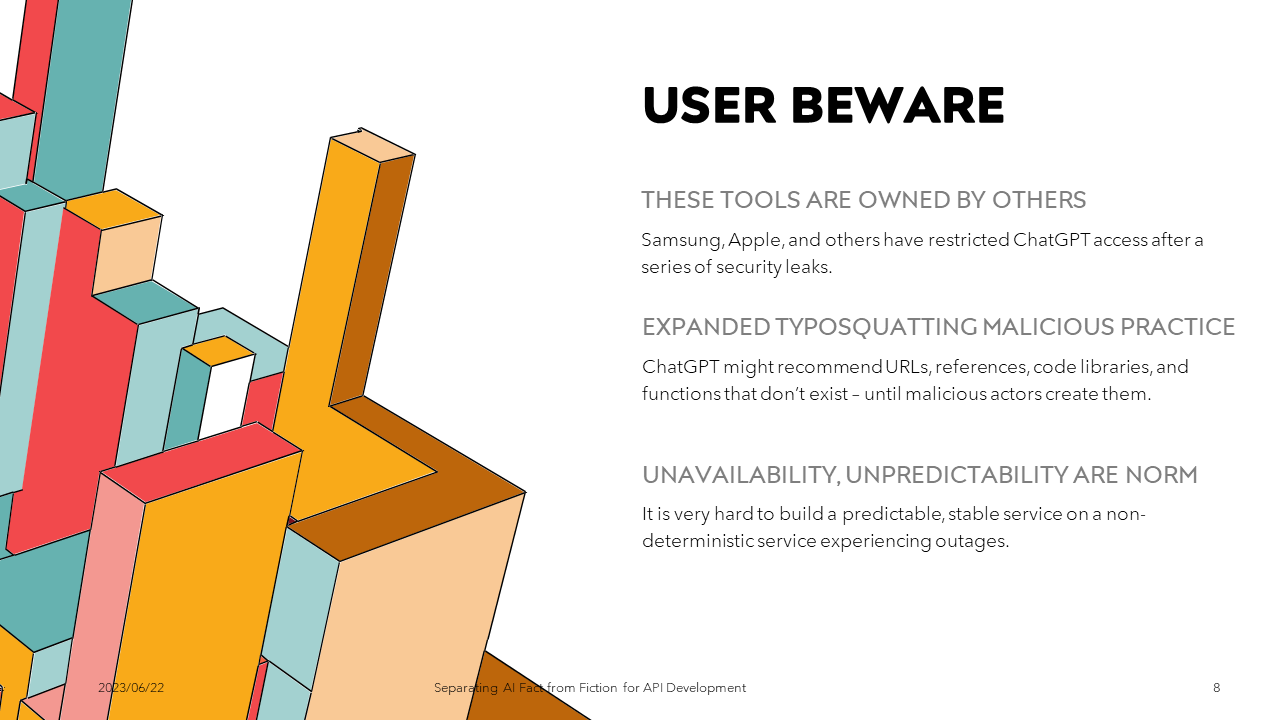
THESE TOOLS ARE OWNED BY OTHERS Some of you might have heard this story. Soon after Samsung’s semiconductor division started allowing engineers to use ChatGPT, workers leaked secret info to it on at least three occasions:
- One employee reportedly asked the chatbot to check sensitive database source code for errors
- Another asked for advice in optimizing code
- A third fed a recorded meeting into ChatGPT and asked it to generate minutes
Apple soon followed suit in restricting ChatGPT access. In response, Microsoft is said to launch a private alternative sometime this summer – a version of ChatGPT that runs on dedicated cloud servers where the data will be kept separate from those of other customers. While that will be nice, a proportional cost will most likely accompany it.
CHATGPT HAS EXPANDED TYPOSQUATTING MALICIOUS PRACTICE
As we’ll cover, asking ChatGPT for package or library suggestions can be easy. This month, some clever security researchers realized that sometimes ChatGPT recommends URLs, references, code libraries, and functions that don’t exist. The story goes from annoying to alarming when we know that malicious actors could create code with those same names, which are subsequently incorporated inside legitimate codebases by naïve developers.
(Update 2024-03-31: A security researcher, realizing the freuqency with which Alibaba’s GPT was recommended a fictional Python dependency, went an created his own version before a malicious actor could. That dependency has now been referenced more than 15,000 times.)
This is like the practice of “typosquatting” but updated for LLM output.
UNAVAILABILITY AND UNPREDICTABILITY ARE THE NORM
In the following examples, you’ll see lots of screenshots, which is very much on purpose.
ChatGPT’s availability has been much better in recent months. However, there are still times when the service is unavailable or returns an unknown error. Having this occur during a live demo is not desirable.
Also, LLMs like ChatGPT are non-deterministic, meaning we’ll get different answers if we ask the same question multiple times. That can be a problem when trying to recreate behaviors.
If I were to use a technical term, I would describe the current state as “squirrely”. I wouldn’t trust it to do a live demo, and I certainly wouldn’t rely on it as part of a 24-7, client-facing activity, at least at this point.

Enough caveats!
I want to briefly run through several much less well-known, but useful ways to apply a natural language LLM, like ChatGPT, to your everyday activities.
None of these things will do your job for you. However, when approached with a bit of creativity, they can take tedious or time-consuming tasks and make them trivial, leaving more time for building APIs.

Let’s start with a simple example and rapidly get to more complex cases.
For me, sometimes I have difficulty remembering a specific word. Often, I’ll have an image in my mind of the word’s silhouette – how it rises and falls with its letters. I usually have clarity on the starting letter, but when I reach for the rest of it, there’s just a gap. I’ll struggle for a bit, use something else, and then get smacked upside the head during dinner or while in the shower when the word pops into my head.
Trying to Google for ‘words that mean kind of like this that start with this letter’ are hit or miss. Sometimes it works, but more often, I get frustrated wading through advertising and content marketing spam.
However, this is a task that LLMs are good at – again, they’re working with statistical probability, and providing the right criteria will create the odds-on match for what you’re talking about.
This also works great for quickly getting up to speed on industry jargon – terms of art that would be useful to know but would take a long time to pick up through meeting osmosis. You’ll also notice here that creating structured output, like tables, is as simple as just asking. No need to try and remember markdown’s syntax – something that I often had to lookup in the past.

The nice thing about these tools is that they provide a base level of competence in communication. Much has been written about the predictable, even cliché, writing that ChatGPT 4 currently outputs. It is true: spend any amount of time with these tools and the framing in the introductory statement, a series of bullet points, and a conclusion restating the main point is an easily identifiable pattern.
However, given how most communication is structured, even this is a step above what I usually see in daily business messages.
From tricky emails to performance reviews to more critical business communication, I strongly recommend not copying the generated output directly. Instead, take 30 seconds to recognize how the stereotypical (yet clear and concise) response has been formatted. Then, customize it with the unique details of your situation. It is slightly more work, but it will help you overcome the tyranny of the blank page – rather than starting with nothing, you’re kickstarted with an example of how someone saying something like what you wish to say has structured their argument.
In the example shown, I was asked to write a blurb supporting the humanities department for one of my alma maters. I was flattered and immediately began to procrastinate – what would I say? I asked ChatGPT for an example, not intending to use what it outputted, but to get me unstuck. While the result on the right is my voice and feeling, I had to go through a crappy first draft to get there. And ChatGPT is great for generating a crappy first draft quickly.
Another approach is to take something you’ve already written and ask ChatGPT or fix grammar or punctuation. You can even ask it to rewrite to clarify the main points or apply more professional polish than what currently exists.
Sometimes it is helpful just to have a starter reference. Things like performance reviews, things to cover in 1-on-1s, internal CMS documentation, and more are all opportunities to overcome initial inertia (the structure) and get to the fun parts – injecting your personality to make it something special.

Chris Busse, a former co-worker of mine, inspired this next one. He uses ChatGPT to create learning plans. There’s a logic here that makes a lot of sense: with the entire corpus of the web used during training, ChatGPT would know which concepts are statistically probable to appear next to each other. All that is then required is providing the correct context.
And it is the context that makes this approach very powerful and efficient. Rather than having to wade through generic, trying-to-be-all-things-to-all people, I can create a tailored, custom plan that covers exactly what I need (and very little that I don’t). In the process, I save time not re-reviewing things outside of what I would want to learn, as would be the case with starting a course from scratch at Pluralsight or Codecademy.
In this example, I have a problem. I learned JavaScript in the aughts. So, when I try to write Node code today, I’m still thinking about functions and callbacks. However, many of the code samples I find or packages I try have the expectation I know promises.
I could attempt to scour the web for a variety of general JavaScript courses, scraping together something useful here and something relevant there. But discovering and reconciling everything together is a lot of work. Instead, I can ask ChatGPT to create a series of steps that would work well for my situation.

Another place where I am more efficient is keeping up with industry trends. I love Ben Thompson’s Stratechery. But with pieces regularly coming in at more than two thousand words, it can be a commitment to keep up. (To be fair, many people probably say the same about my newsletter.)
Rather than setting aside an hour when the latest email drops, I can ask ChatGPT to summarize the contents to only those unique points. That takes this recent article from 2353 words to a much more skimmable 393 words. If, after reading the summary, I see something of interest I can go back and have a better idea that my investment of time in the large piece will be worth it.

Beyond summarization is inference. Suppose I am a product manager or tech lead interesting in understanding my own or competitor products. In that case, I can quickly get an idea of perception with any collection of customer reviews.
Here I have the 1st edition of the ‘Continuous API Management’ book. Copying in the review contents, I then asked ChatGPT to summarize the top 3 things people liked and disliked about the book. That is not just rehashing what is said but inferring whether those comments are positive or negative. ChatGPT also must infer whether one comment is saying something like another.
I haven’t shown it here, but one of the comments was also in French. I didn’t translate it before handing it to ChatGPT. However, after I did, I discovered sentiments in that foreign language comment appeared in ChatGPT’s summaries. That is another thing I want to emphasize – ChatGPT performed that translation and incorporated that sentiment into the results automatically.
That can be highly beneficial when doing competitive analysis. Imagine being able to take a user forum filled with customer feedback and easily identifying new feature opportunities. ChatGPT, in this case, is not just summarizing the reviews, but can infer whether the comment is overall good or bad.

Alright, enough potpourri! Those things may be helpful, but how do we use a natural language LLM, like ChatGPT, to create APIs? I’ll get into that with this next section.
To get started designing, we should follow a repeatable, predictable process.
I’ve long been a proponent of an API-Design-First approach when creating APIs. In 2020, I had the good fortune of being asked to review James Higginbotham’s book, Principles of Web API Design. In that book, James codifies a rich API-Design process, referred to as the ADDR (or ‘Align-Define-Design-Refine’) model. While the result is a detailed and complete set of exercises used to explore a space before creating an API, a fair amount of work is involved. Further, due to the high levels of communication necessary, it could be a challenge for remote or solopreneurs like myself.
Are there ways we can leverage an LLM like ChatGPT to aid to provide rapid collaboration on some of these tasks?

To work through the ADDR process, it makes sense to have a specific example.
As a writer that frequently links to other material in my newsletters, I am very aware of the prevalence of tracking and advertising codes that often are included as query parameters. Whether bookmarking or resharing the links in my newsletter, I don’t want to include these tracking codes or highlight fragments. The extra cruft obscures the original URL.
In my initial vision, the service would accept a URL, strip off all the unnecessary query params (probably with a regular expression) and return a ‘clean version’. When I have that API, I can call it with everything from browser plugins to native applications.

Creating Jobs-To-Be-Done (or JTBDs) from scratch can be tedious to write. In addition, let’s remember what an LLM is – a pattern matching-machine. So let’s ask ChatGPT what other text – or what other jobs – is commonly associated with the text we’re interested in.
ChatGPT has created a good JTBD for our initial prompt. ChatGPT also listed several subsequent jobs that someone interested in URL simplification might also want to use. These include:
- Validation
- Redirection Handling
- Blacklisting
- Canonicalization
- Generation
This list includes several services I wouldn’t have thought of. For example, the ‘URL Canonicalization’, which follows references of rel=”canonical” in a page’s header, would be useful. Authors publishing to Medium, for example, do this all the time.
With these initial job stories in hand, I then iterated. That included replacing the term “blacklisting” with “blocklisting”, replacing “URL Generation” with “URL Shortening”, and more. Through this back and forth, I’m getting feedback that clarifies my ideas about what the service should and shouldn’t do.

Creating job stories helped identify the desired outcomes and the digital capabilities necessary to produce those outcomes. Following the ADDR API design process, the next step is to detail the digital capabilities as the activities and activity steps required to do these jobs.
Activity steps decompose activities into tasks that need to be performed to complete the story. Once all necessary activities are completed, the job story outcome will be met.
By decomposing the problem in this way, we continue to uncover assumptions or misunderstandings that we can correct before jumping to a design or code output.

As I continue to work through the steps, it becomes clear that I have a problem with the Blocklisting. While the JTBD description made sense, having ChatGPT expand the result into activity steps has uncovered an assumption that I would build and maintain a blocklist for people to submit a URL to. That’s beyond my scope. Instead, I want to leverage existing work – surely, specialists are already maintaining lists of malware and spam sites.
Having ChatGPT rewrite the JTBD and activity steps is easy enough. However, I know that services that maintain blocklists of bad URLs should exist, but I’ve never used them. Where would I start? So I asked ChatGPT that too.
ChatGPT provided a list of a half-dozen results, which – I want to emphasize this because it is crucial to do because of the ‘typosquatting’ issue mentioned earlier – I then independently verified to ensure they were real sites.
After identifying the option that made sense for my project, I asked ChatGPT to update the activity step participants with that additional information.
This may seem like extraneous steps – however, the reason that we’re following a formal path like this is precisely for this reason – to surface assumptions. I could have asked ChatGPT to try and generate code from my initial idea. However, by continuing to chip away and refine the underlying assumptions, we’re ensuring we can get a better result.

After additional, similar refinements to both the jobs to be done and activity steps to make sure any assumptions were aligned with my expectations, it was time to take a moment to reassess what was being proposed.
Suppose I was working with an engineering team and stakeholders. In that case, this is the point where we would walk through our activity steps, or the output of an activity like event storming, and begin to identify our API boundaries. We would see places where we might have shared terminology. Similar language is a clue that there is a bounded context that should be grouped together.
Given that ChatGPT can infer words that are statistically similar, let’s use it to analyze what we’ve created thus far.
While iterating with the steps, I had already begun to consider redirection and canonical header handling as similar functionality. What I had not considered was what ChatGPT pointed out – that all these subsystems would require URL validation before performing their respective tasks – which was a great point.

There’s more in the ADDR model, like building style-agnostic API profiles and identifying emitted events. Those are essential steps for larger, more complex initiatives. For demonstration purposes, I will jump ahead to create a high-level API description to the OpenAPI specification.
I directed ChatGPT to use our refined JTBD and activity steps to create an OpenAPI description. To make things interesting, I also required it to use the 2.0 (or ‘Swagger’) version of the specification.
The results could have been better. While the OpenAPI description validates, it is clear that the jump from activities to resource design in a RESTful manner was too much. I hadn’t provided context in what I expected from a REST-like API.
Functionality like “URL simplification” and “URL Blocklisting” became RPC-like endpoints where a request would POST to ‘/simplify’ and ‘/check-blocklisting’. Also, I’m not a fan of baking version numbers into the path, but there’s “/api/v1” right there to start.
Important elements were also missing. As ChatGPT warns, “Here’s a basic example of how you might describe this API using the OpenAPI 2.0 (Swagger) specification. This only covers some basic paths and doesn’t include all potential error responses, security definitions, tags, etc., that a full OpenAPI spec might include.”

More work is necessary here; luckily, we have a tool that has ingested the entire internet (give or take a forum). Others have experienced and written about what they do in this situation. That means we should be able to ask for what lies along that probability. Specifically, when dealing with operations related to validation, how do other services model that without making an explicit “validation” resource?
The answer provided by ChatGPT isn’t the whole answer, but it did point the way to a resourced-based design approach that won’t lead to an explosion of custom-named, function-based endpoints in the future.

I’ll spare you the iteration at this point. Bottom line, using the design performed in the previous steps, I entered my IDE and quickly created a revised OpenAPI description that captures the functionality I want to provide. In addition, the design matches how I would expect the affordances to be modeled.
I can now take this intermediate format –machine parsable while still being human-readable – and begin working on my implementation.

There’s been a lot written about how well (and not so well) natural language models like ChatGPT are at writing code.
With our OpenAPI description, and a handful of my other code generation experiences to draw on, let’s see how far we can get.

Much like our design process, having a series of steps to follow is beneficial– in all but the simplest cases, going from an idea to telling the LLM to “make me some code” is too much of a leap. Proceeding along a series of steps to unpack assumptions and clarify direction goes a long way toward creating more valuable (and less buggy) code generation.
One useful approach I’ve found was written by Xu Hao and shared on Martin Fowler’s website.
We want to:
- Begin with context and instruction
- Ask ChatGPT to outline its approach, splitting the interactions into multiple addressable steps
- After refinement, regenerate the plan with names for program elements
- Then ask, step by step, for tests and implementation code

The first step in developing code, following Xu’s model, is to provide context and generate a series of steps. That includes providing a brief of our intent, our desired tech stack, and the required output format.
Based on our context, we now have a preliminary plan. Much like our design process, we should proceed through each of these elements and, where appropriate, update any assumptions or misunderstandings. Doing that at this level is much easier than modifying generated and possibly interrelated code.
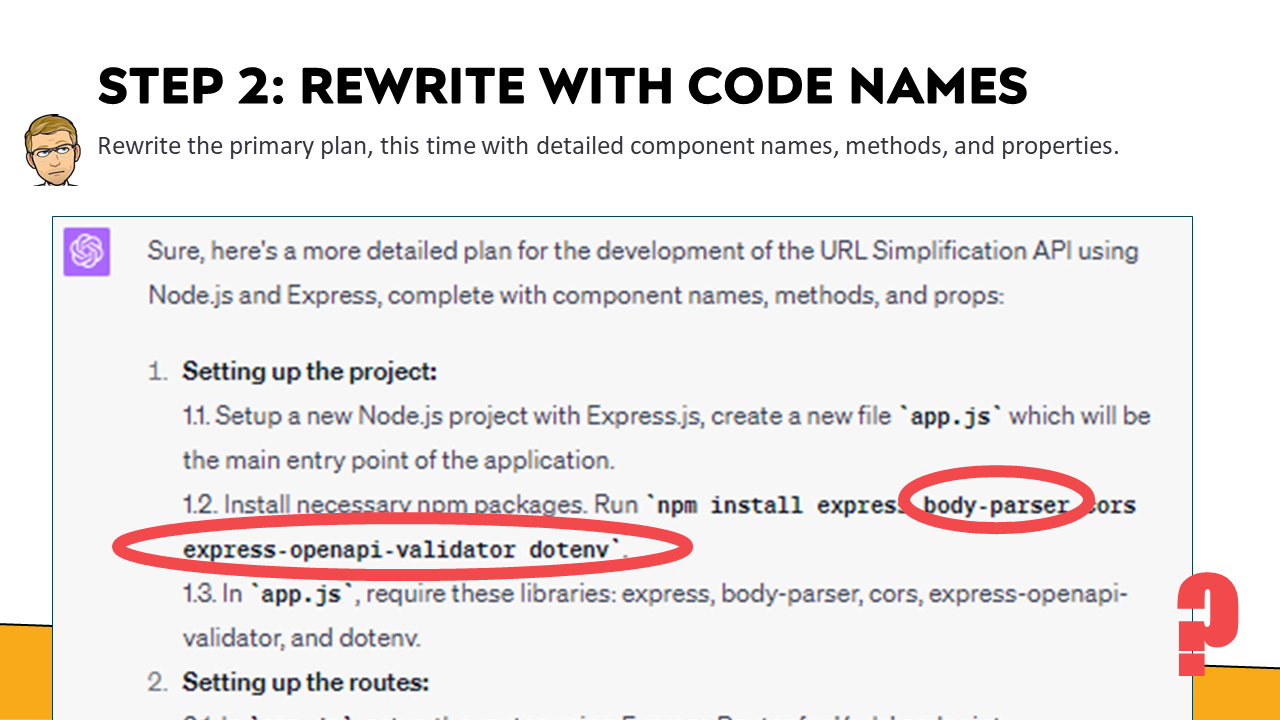
As before, asking for an update to the plan with components, methods, and properties allows us to preview the upcoming code execution and, where necessary, make changes to avoid problems.
At this step, ChatGPT has helpfully included numerous items related to our project. However, even at the beginning of the output, there is some cause for concern. In the creation of the project, ChatGPT has included several packages that are relevant. Express makes total sense – we asked for it. Body-parser does, too, as we’ll be parsing the body of submitted requests. However, as of September, 2017, Express has included body-parser as part of the default Express package.
What’s more, there seems to be some confusion. While we’re using an OpenAPI description to provide additional context for code generation, nothing about our service requires using an OpenAPI file in production, let alone the need to validate one.
On a more positive note, including “dotenv” is a welcome surprise. We will deal with keys and secrets if we call other 3rd parties for processing. But we need to be aware that some of how that is handled will depend on the cloud service we use for production.

After multiple rounds of providing instructions for our more detailed plan, we get to the point where we have a very robust understanding of what the code should be doing and how we’ve organized it. Note that this isn’t just throwaway work for satisfying the LLM – this also provides a robust set of documentation to refer to later, like for onboarding new developers.
The next step is to create the necessary test cases which exercise the functionality that we’ve described. In addition to asking for a plan for end-to-end testing using a tool like Postman, I can easily tell ChatGPT to generate sample test information for use as part of a test runner.

Some cautions that we need to be aware of while creating code. These LLMs can only learn from the past. And while they have a vast amount of information as part of their training data, that data includes those old tutorials and quickstarts as we saw with the inclusion of ‘body-parser’ in our express code. The model has no concept of deprecation over time, at least not yet – something that is a problem for programming languages.
Another issue is that larger projects require more tokens. GPT-4 has a token limit of 8,192. Another variant increases that to 32,768. That is more but both variations can quickly be consumed on tricky problems.
Once ChatGPT receives enough tokens, it begins to lose context, starting with the earliest material. And given the importance of maintaining context to create logical results, this can be a big deal.
You can check the number of tokens used with OpenAI’s tokenizer tool. For our example, my simple 110-line OpenAPI description already constitutes 1,522 tokens. Bigger, more realistic applications are going to consist of significantly more tokens. That is why, when performing this kind of development, the problems must be decomposed into highly focused, discrete work units.

I could keep going. This entire thought exercise assumed that I was creating a new service from scratch. I didn’t even address situations where we might have an existing codebase. There’s a host of different applications, from creating documentation to identifying redundant points, from translating to different languages to inferring operations based on logs that I could go into.
However, in the time that we have left, I want to return to a high-level conversation and discuss the implications of LLMs being widely used in software development.

In the immediate future, we will see all manner of existing software tools incorporating ‘AI’ or ‘Copilot’ features. It is just too much of a compelling selling point now. Some of this will be genuinely beneficial and create new opportunities for productivity. In other cases, existing algorithmic automation will get rebranded.
With all of this ‘AI’ advertising, we need to be able to evaluate the claims made. There will be helpful functionality. There will also be a tremendous amount of ‘AI snake oil’.

Much of what we discussed in both the design and development sections has the potential to create better results. However, it is crucial to recognize that both of these steps pale when discussing software’s total cost of ownership.
To be clear, 90+% of the cost of any code, let alone APIs, is in the maintenance and operation. We treat getting into production as checking the box, completing a goal, and being “done”. Then, the thinking goes, the more things we can get “done”, the more productive we can be.
Creating something faster is not the boon to business that you think it is. LLMs, done incorrectly, are the equivalent of throwing more things at the wall, faster.
We should aspire to create better software, not necessarily more.

Of course, the more we use these tools, the more likely these model’s outputs will be included in the training sets. When this happens, it leads to an interesting phenomenon known as “model collapse”.
Datasets that contain LLM-generated text experience worse performance; it is almost like making a copy of a copy of a copy. Subsequently, volumes of data compiled before 2020 will be at a significant premium for people looking to continue training models. And the more we put the output of these tools out into the world where they can be scraped for the next generations of LLMs, the more problems those LLMs will have.
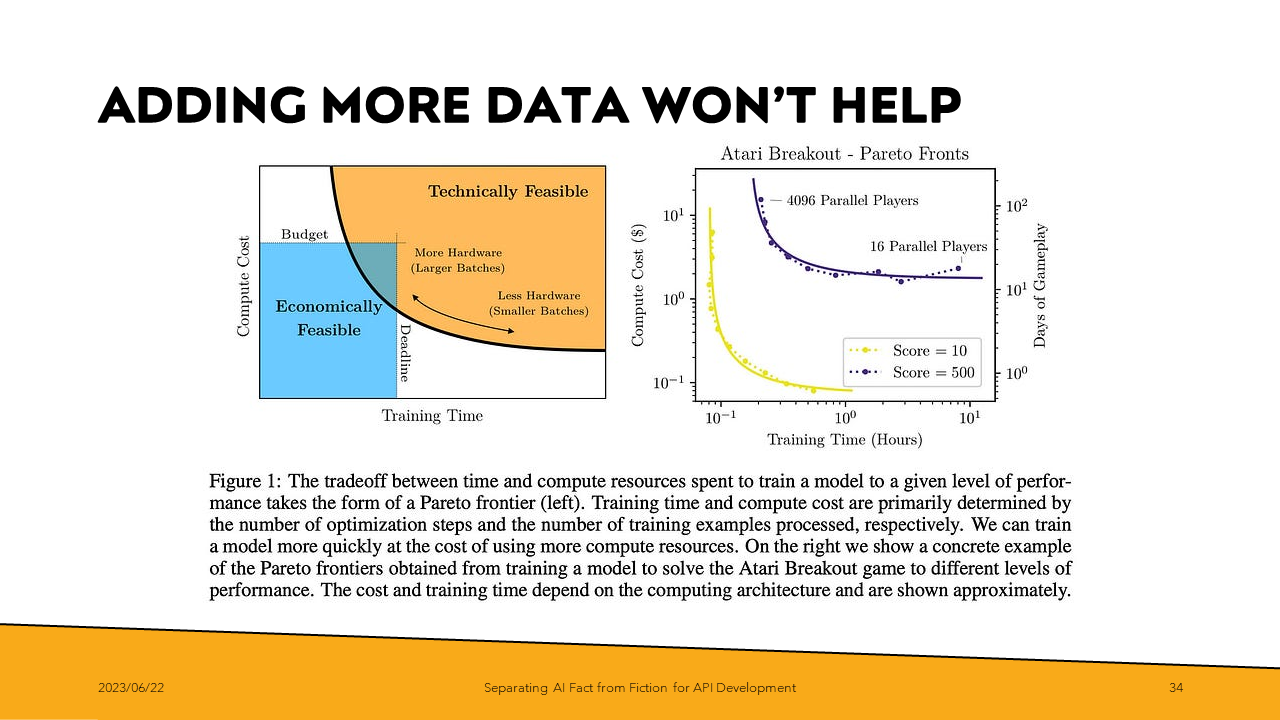
But even if we could uncover another Reddit or Wikipedia, which somehow had avoided being used in training models thus far, there is the question of whether we’d see the same leaps in perceived performance that we have seen to date.
As suggested by papers in the space, we could be reaching the point of diminishing returns in raw training data set size. There is a high likelihood that performance improvements in the immediate future will be because of targeted, task-based optimizations for specific industries, as opposed to larger training data sets.
All of that is some interesting, challenging technical problems. I’m not saying that we won’t see improvements in LLMs in the future. What I am trying to impress upon you is that the rate of progress isn’t up and to the right forever – at least not using current techniques.

But even with what we have, what we have is pretty amazing. Simon Willison perfectly captures the sentiment I’ve felt while exploring these tools
‘AI-enhanced development makes me more ambitious with my projects.’
“As an experienced developer, ChatGPT (and GitHub Copilot) save me an enormous amount of “figuring things out” time. For everything from writing a for loop in Bash to remembering how to make a cross-domain CORS request in JavaScript—I don’t need to even look things up any more, I can just prompt it and get the right answer 80% of the time.
“This doesn’t just make me more productive: it lowers my bar for when a project is worth investing time in at all.”
I’m not a cutting or even leading-edge developer. My production code days are at least a decade behind me. I cut my teeth in the era of responsive web design, database normalization, and three-tier software architecture apps. I still think of software in model-view-controller terms. I moved to organizational concerns before the big shift to cloud, containers, complex frontend libraries, and intricate deployment pipelines. As such, launching a new project is intimidating for me. Even attempting to follow getting started tutorials can be a frustrating experience; so many of them start from a place of high background knowledge and assumed pipeline guardrails that I have difficulty following along.
Being able to quickly bridge that experience gap by asking for what I need to know - rather than having to stitch together the missing puzzle pieces from here, there, and everywhere else – is huge. In some ways, it is personal for me.
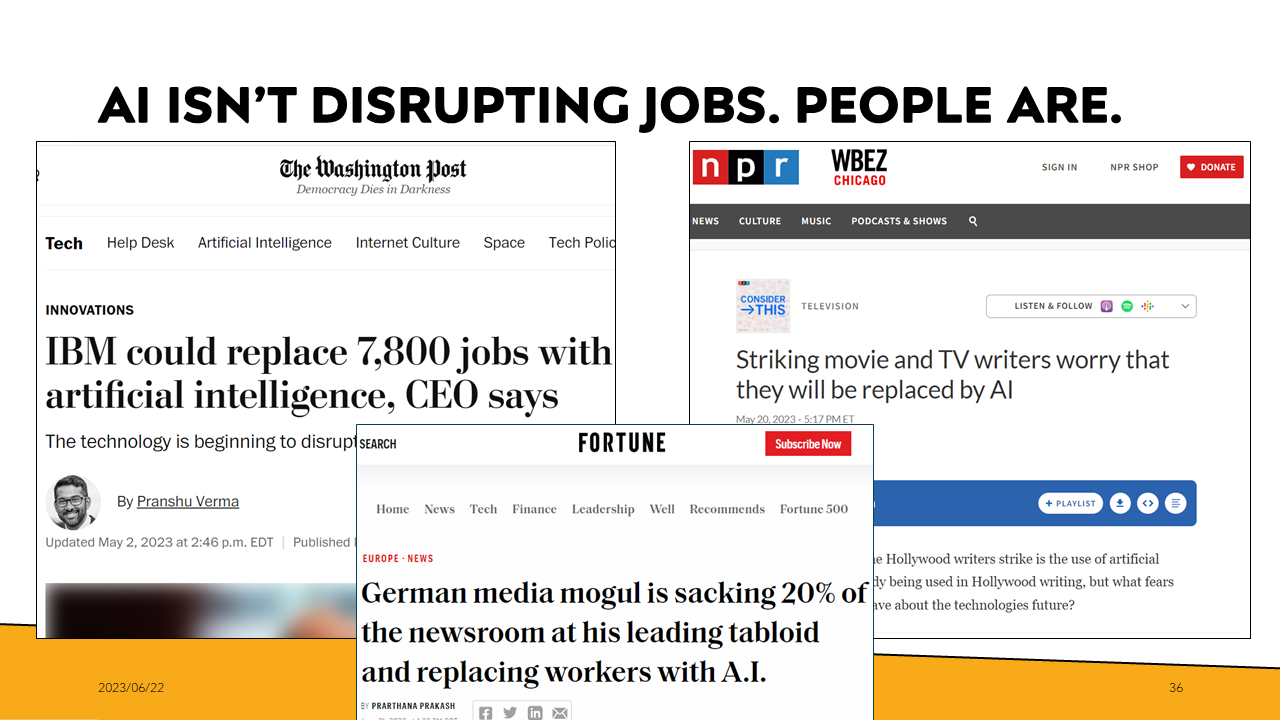
This brings me to my last point. We’re not talking about a model when we say ‘AI did this’ or ‘AI disrupted that’. Whether we’re talking about laying off nearly 8,000 people or undermining a workers’ strike, those are decisions being made by people. And we need to hold them accountable for their actions.
From Emily Bender, again:
“Rather than asking, ‘can AI do that?’, the more appropriate question is ‘Is this an appropriate use of automation?’”
That applies to a lot more than just ChatGPT. From our dev pipelines to our call center support, how do new forms of automation enable us to BEST serve our customers and what they are trying to do? In whose interest is it to lay off journalists, creatives, and even technology professionals?

‘Dismissing today’s current crop of LLMs, or “generative AI” as only capable of “telling lies” or “hallucinating” projects far more personhood and sentience - a will or agenda present during interactions - than what exists. In a world that has seemed more chaotic and randomly cruel, particularly in the last several years, our brains are working overtime to see a pattern, an intelligence, an intent anywhere we can find it. Sadly, those looking for a savior (or an opponent) will be disappointed.
What does exist is a set of tools - useful, powerful tools that tighten the feedback loop for creators. Further, these tools leverage the power of language. Rather than requiring a priesthood versed in ritualized incantations, the promise is that anyone who speaks can create software. While much of the low or no-code effort has focused on greater visual metaphors, from Visual Basic to Scratch, the promise with tools like ChatGPT is to forgo that learning ramp entirely.”
Grady Booch, an American Software Engineer perhaps best known for developing the Unified Modeling Language, once said, “the entire history of software engineering is one of rising levels of abstraction”. There is a solid argument to be made that LLMs represent the next major abstraction in software development. The key to unlocking ever greater levels of software potential was not enriching our communication with more rigid semantic meaning. Instead, it was about training the machines to be more comfortable with our language’s ambiguity.
In conclusion, as those most able to understand these tools’ nature, we must use them wisely – to empower where necessary and avoid perpetuating a status quo of inequality and apathy.

Thank you for and inviting me back again to speak this year and the opportunity to share some of my most recent work.


