
Last year, I gave two public presentations. I posted ‘APIs are Arrangements of Power’ previously. The clean-up on the second, delievered when in-person gatherings still happened, languished due to (gestures wildly at the surrounding air) things. During the holidays, however, I made an effort to finalize and pull everything together.
A recording of an abridged version of the talk is embedded at the bottom. A portion of the talk even made it into the book, Accelerating Software Quality, by Eran Kinsbruner.
Without further ado, here is ‘Why AI Success is API Built’.

Hello everyone! My name is Matthew Reinbold, and tonight, I will be talking about Why AI Success is Built on APIs.

We’re briefly going to go over:
- Why AI is such a big deal right now just to level set
- Talk about the challenges of creating AI models
- Why some of those challenges lead to APIs to deliver AI functionality

I’m passionate about these issues because they impact my work. I am the Director of the Capital One API and Event Streaming Center of Excellence. It is a unique position that requires me to be part enterprise architect, part business analyst, and part internal developer evangelist.
My team and I work with our 9000+ developer community to ensure that the message-passing systems built exhibit consistency and cohesion. We provide training, collaborate on API descriptions, evolve oversight processes, and facilitate co-creation on our design standards.
I also do a fair amount in the broader API community. I write a newsletter called Net API Notes. I curate Net API Events, a list of in-person events for API professionals worldwide. I also tweet a fair amount, mostly about APIs but sometimes, occasionally, Lego.
I also make some legally dubious laptop sticker parodies for my Patreons.

It is important that I first establish what I’m talking about when I talk about when I say ‘AI’.
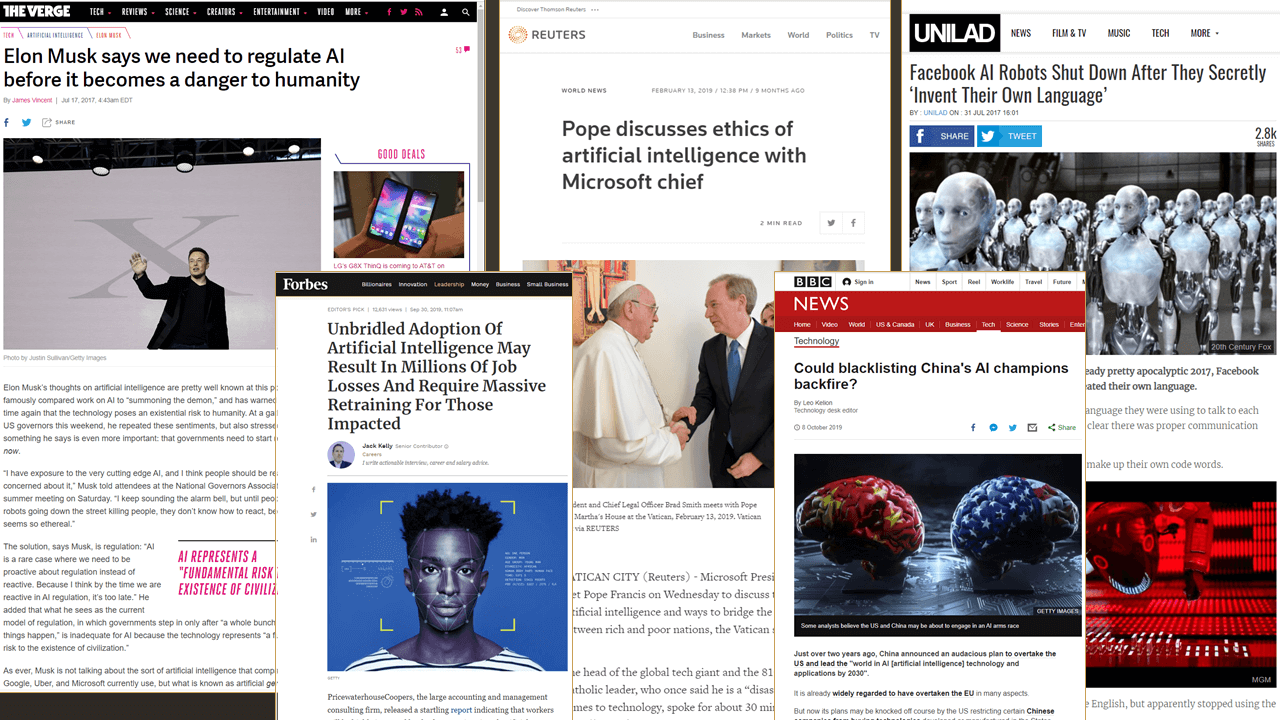
AI has generated almost as much excitement as clickbait headlines. You would be forgiven to think that we’re all one errant compile away from Skynet. I mean, even the Pope is talking with Microsoft. When something crosses over into popular awareness, it is significant; even if that awareness is imperfect.
Before going further, we should be on the same page. AI is a broad brush that paints many things. Usually, when you see these alarmist articles about Skynet and Terminator death robots, the authors are postulating about “Artificial General Intelligence”. This is software that can “think” in a manner we associate with people.
We are still quite far from that future. What I will be talking about tonight is much more narrowly focused. So narrow, in fact, that practitioners refer to it as “narrow AI”. Even more specifically, I will discuss a popular technique, often conflated as AI, called “machine learning”.
Machine learning has real, tangible benefits for companies. It also solves interesting challenges. As an additional plus, it probably won’t end human life as we know it.
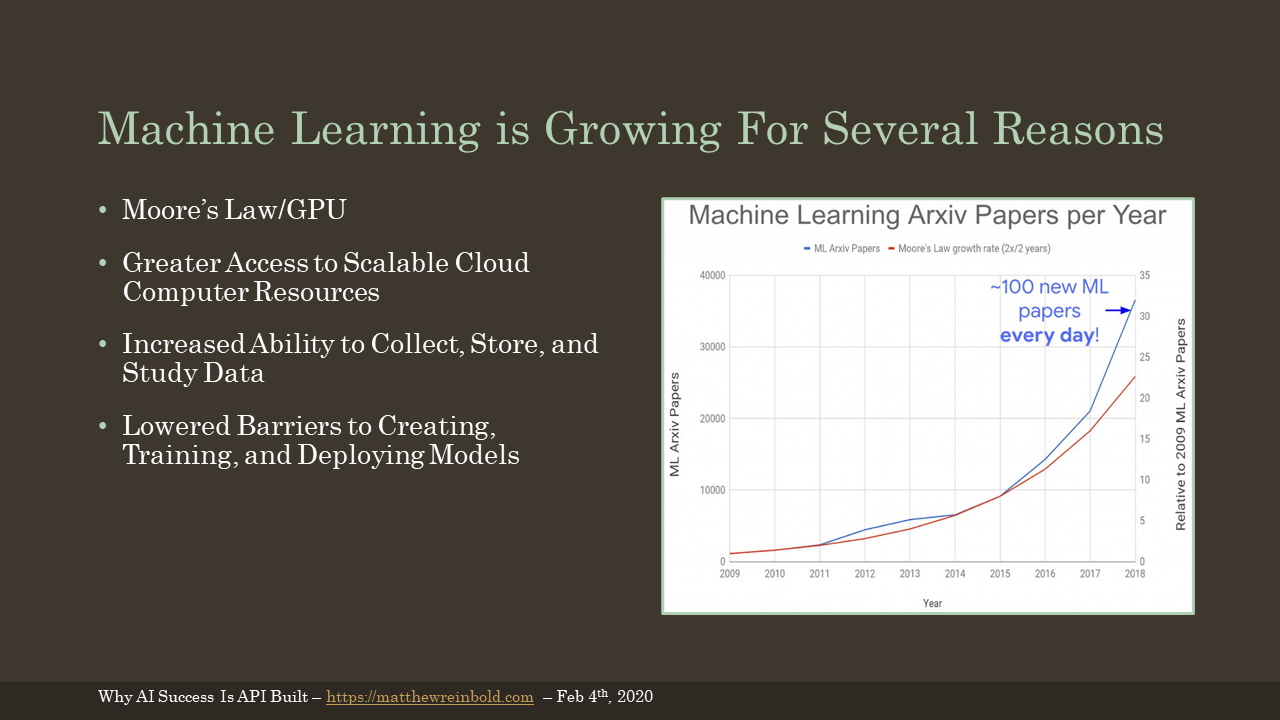
If you were trying to follow every single new paper released in the machine learning space, you’d now be trying to absorb 100 machine learning papers every single day. While the concepts behind machine learning have been around for some time, the current Cambrian explosion of published work has many factors.
- Moore’s Law - The speed of compute is faster than it has ever been, particularly in GPUs
- Cloud Compute - Everyone can get access to these fast processors
- More Data - For better or for worse, we are better about to scale both data collection, storage, and analysis
- Greater Ease in Model Creation - More people are trying more stuff more of the time
(Chart from the blog post ‘Too Many Machine Learning Papers’)
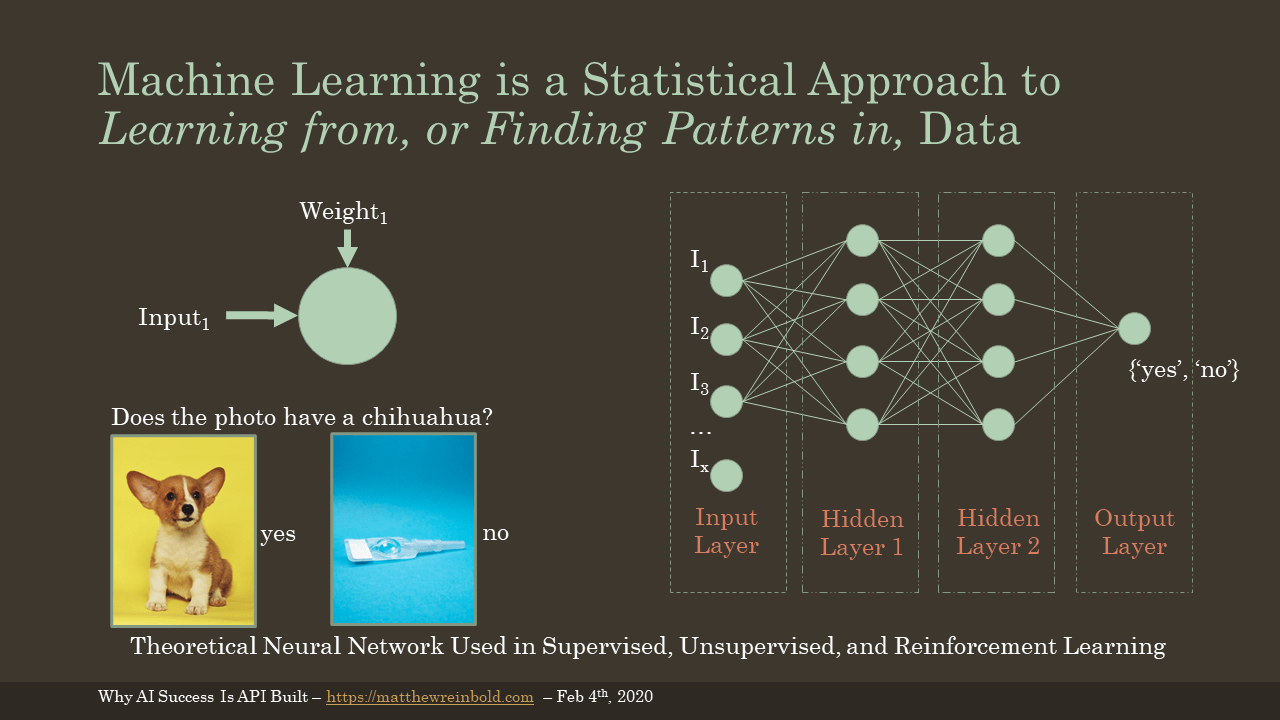
A full explanation of how machine learning, and how its various permutations work is beyond this presentation’s scope. However, as we begin to discuss why these things take so much compute or why they’re so energy expensive, we need some theoretical model in how they’re composed.
Suppose, for example, we had to create a service that could determine whether a provided picture was of a chihuahua or not. The output is either “yes” if a chihuahua is present or “no” if not.
Using machine learning, we would create several nodes for our input layer. Each of these nodes corresponds with an individual pixel of the image provided. A weight is assigned to each of the nodes. The value of this weight is based on how important that node, or individual pixel, is to determining whether a chihuahua is present. Pixels framing the outside might have a low weighted value, while those around the inverted triangle comprising the two eyes and snout would be worth more.
Before going further, I think it is important to note we’re already dealing with some large numbers with only our input layer. My first digital camera was a Sony Mavica in 1999. The max resolution of a picture saved to the floppy drive was 640x480. If we were processing images in that resolution, we’d have an input layer of 307,200 nodes. Those are 307,200 weights that need to be tuned to develop a model. And as you might imagine, pictures taken with modern mobile devices have millions of pixels.
However, we’re only getting started. We take the RGB values in a given node, compute a result with the weight for that node, and then pass that value to every other node in the subsequent layer to be processed. There may be many of these “hidden layers” between the input and the output. Each node in each layer mathematically computes its result. This continues until all the results are recombined into a value in the output layer.
This output layer contains the probability of whether the input meets our criteria. If it is above a particular percentage, we might say, “yes” the image did contain a dog. We continue to iterate on our weights until we are satisfied with how often our machine learning model successfully matches our labeled sample data used for training.
We’ve used machine learning to create a model to detect if our picture features a chihuahua…
(For more explanation, see the YouTube video course, Crash Course: AI)
(Chihuahua Photo by Alvan Nee on Unsplash)
(Photo by Reproductive Health Supplies Coalition on Unsplash)

…or a muffin. It is essential to point out that through all those mathematical calculations, machine learning doesn’t understand what it is looking at; at least not the way we do. It has only identified patterns where two darker dots consistently appear above one other dot (eyes above the snout).
In her book You Look Like a Thing and I Love You Janelle Shane described a similar problem. Microsoft has an image recognition product that works similar to our example: it takes an image and suggests what might be in it. One day, while using this product, Janelle noticed that it was finding sheep in photos that definitely did not have sheep.
After experimentation, Janelle hypothesized that the machine learning model was trained with lots and lots of pictures of sheep in green, grassy countrysides. The model did not “learn” the sheep’s visual properties, but mistakenly correlated the landscape with the sheep label. Subsequently, when Janelle gave the model pictures of sheep in cars or livings rooms, the model labeled the animals as dogs and cats.
(Image from the ‘Chihuahua or Muffin?’ tutorial.)
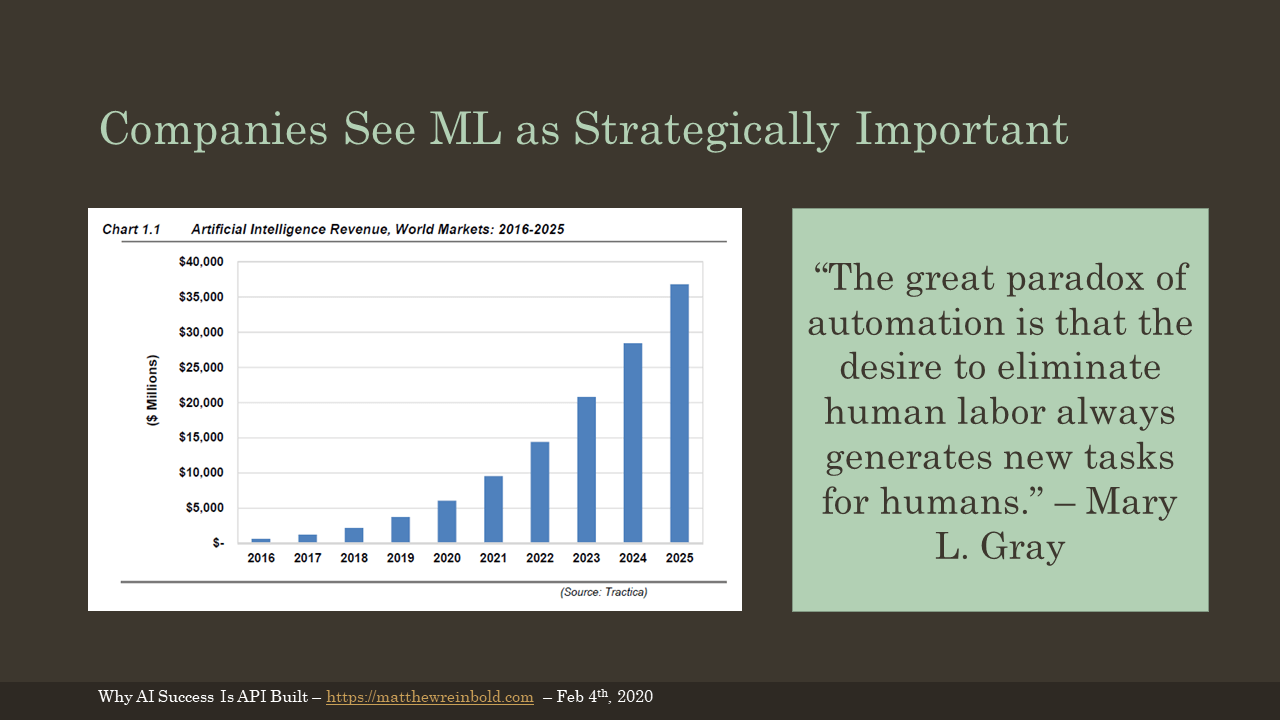
Despite this, machine learning is still a very big deal™ for companies. According to an Accenture global research survey, 85% of business leaders expect AI to open up new products, services, business models, and markets. Another 78% expect AI to disrupt their industry in the next ten years.
Further, a report from market research firm Tractica forecasts that the annual global revenue for artificial intelligence products and services will grow from $643.7 million, in 2016, to $36.8 billion by 2025. That’s a 57-fold increase and makes AI the fastest-growing segment in the IT sector.
And no, AI is not coming to take our jobs. As the quote from Mary Gray says, automation doesn’t eliminate jobs; it changes the form those jobs take.

Machine learning promises to lower costs and produce better outcomes. It’s because AI can recognize subtle patterns in vast volumes of data.
Princeton professor Arvind Narayan created an excellent presentation late last year, entitled “How to Recognize AI Snake Oil”. He identifies where machine learning techniques are practical, where they have problems, and where they may be ethically dubious.
Enhancing or scaling perception is a great application of machine learning. These have clear success criteria; either the model successfully does a thing or needs additional training. Automating judgment, or asking a machine to call balls and strikes when there is some gray area, is more complicated.
Then there’s predicting the future. You may use a machine learning algorithm to review someone’s social media feed and identify how often a beer bottle is pictured. That is perception. Assuming that a high percentage of beer bottle appearances makes an individual unfit for employment is predicting an outcome. That is problematic, as research has shown. Machine learning, despite its promise, cannot tell the future. It can only find correlations in the past.

It is also essential to use common sense when considering machine learning. Martin Zinkevich is a research scientist at Google and author of “Rules of Machine Learning: Best Practices for ML Engineering”. He urges several useful heuristics when evaluating whether machine learning is appropriate for a task, like:
“If your system has more than 100 nested if-else [statements], it’s time to switch to machine learning.”
For example, imagine you’re a smartphone developer, and you’re tasked with recommending the next application someone should use. You could consider the time of day, the weather, user movement, sentiment of their social media accounts, their text and call volume, the proximity of that communication in a social graph, etc. Those could all be inputs to a complex model.
Or you could recommend the most frequently used apps. If a simple heuristic, like “recommend the most recently used items”, is successful 70% of the time, any model built has to significantly outperform it to justify the increased complexity.

What form does that complexity take? Let’s talk about the challenges to developing machine learning.

There are four big challenges to creating successful machine learning models. They are:
- The volume of data to collect and refine
- The compute cost to process
- Regulatory, privacy and/or ethical concerns
- Operationalization.
To illustrate this, let’s talk about Google’s Meena chatbot. A sample conversation between Meena and a human is shown in the slide. Google used 341GB of text to train the model. In doing so, they consumed $1.4 million in cloud computation. That’s a lot of money. It is also a lot of power. For comparison, it would take the average American household 28 years to burn the same 292,912 kWh of power. I might argue that the conversation is not noticeably better than Eliza, a program crafted at MIT in the 1960s. As such, there is an ethical question of whether the results warrants that level of energy expenditure (and subsequent carbon footprint).
And that’s before we even get to operationalization and the challenges of doing Continuous Delivery for Machine Learning.
(More on Meena from a ZDNet article)
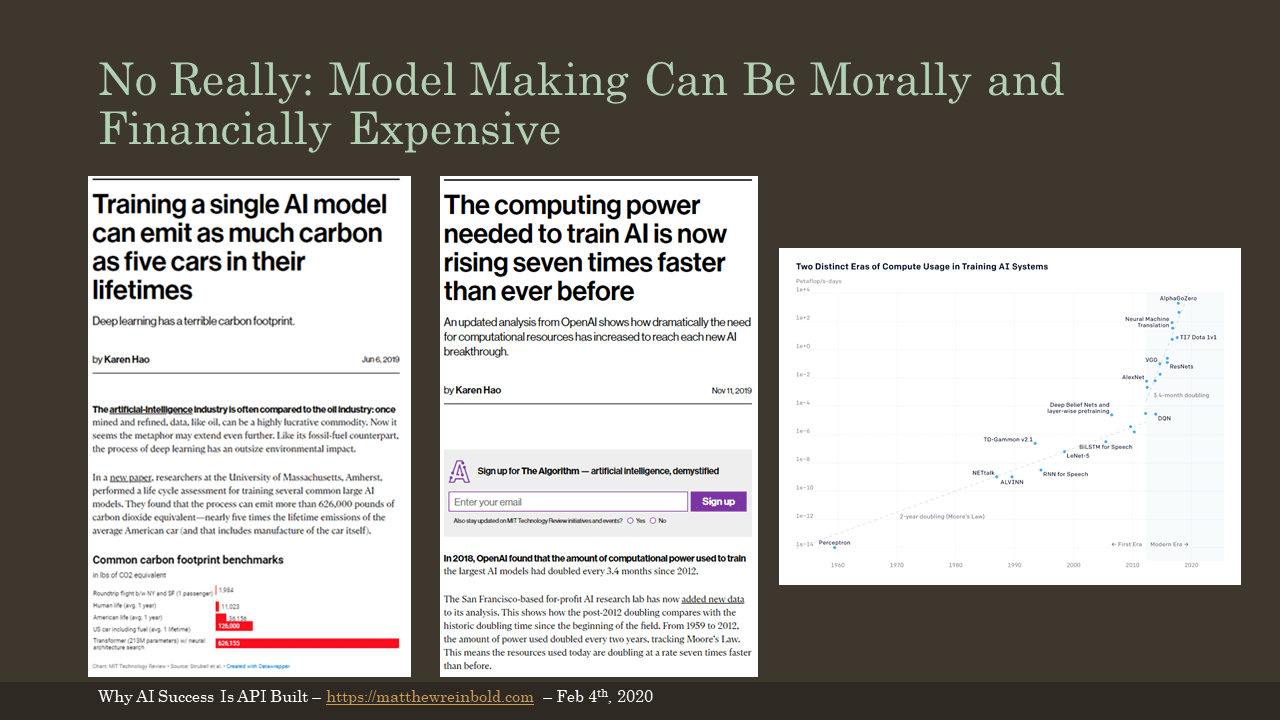
Please consider where the compute for your models is being run. If the training can be done anywhere, research which AWS regions carbon offset, for example. For reference, that is not US-EAST-1. If the training is geographically agnostic, take a few minutes and click the necessary boxes to a configuration more carbon friendly.
(Articles pictured in this slide include Training a single AI model can emit as much carbon as five cars in their lifetimes and Computer power needed is rising seven times faster than ever before)
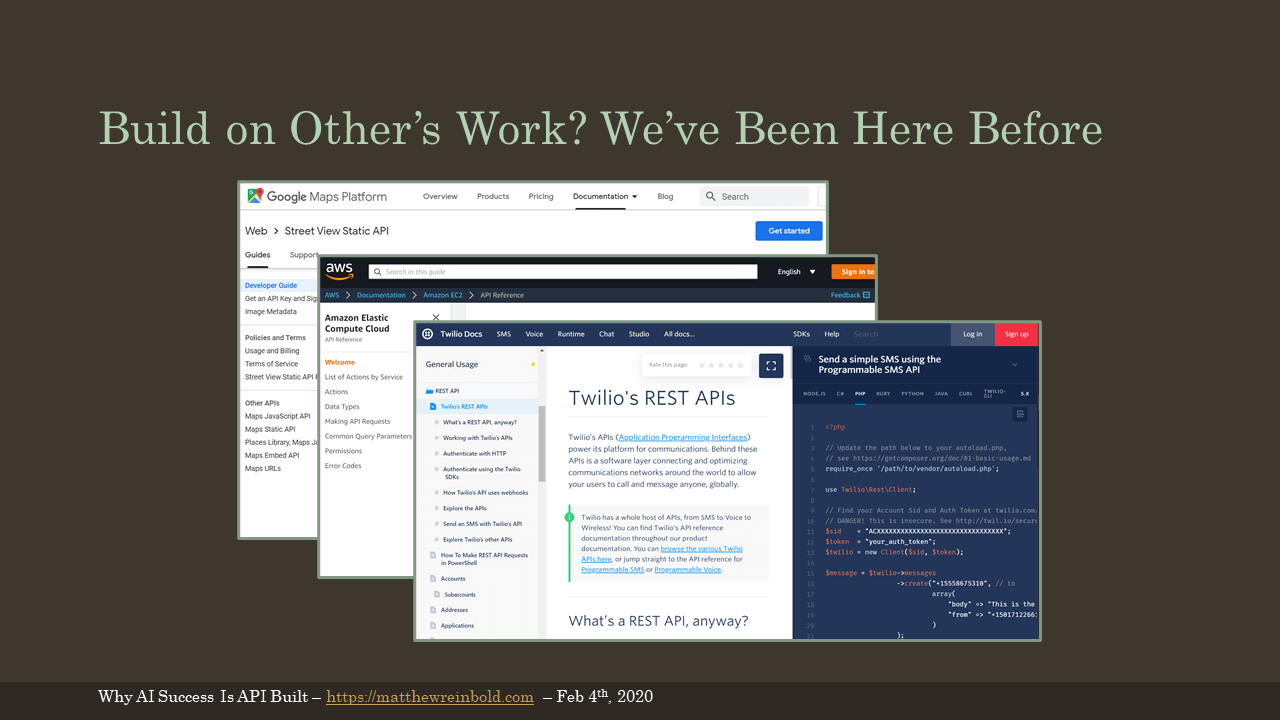
Also, consider building upon others work. It may be hard to remember, but there was a time when the idea of having a picture of every single inch along every single street in every single place was a problem of seemingly infinite scale. Imagine if every application with a street view had to stand-up and operate their own fleet of vehicles and cameras. Yet today, anyone can call a Google Maps API.
Similarly, we aren’t that far removed when small and mid-sized businesses maintained their server closets. Handling things like seasonal traffic or DDS attacks was an individual challenge. Now we have APIs on cloud-providers, like AWS, to call.
Finally, imagine if every application that wanted to send a text message had to negotiate individual deals with each and every telco provider? The barriers to innovation would be horrible. Better to let someone like Twilio do that once, and then we build upon the abstraction.
In the same way that these companies have exposed services via APIs, the future very much looks like leaving the big, precarious, and expensive data collection and model building to the experts. Then we consume that model through an API.

APIs are an enabling technology. AI doesn’t reduce or eliminate the need for APIs. More AI use demands more sensible and well-designed APIs.
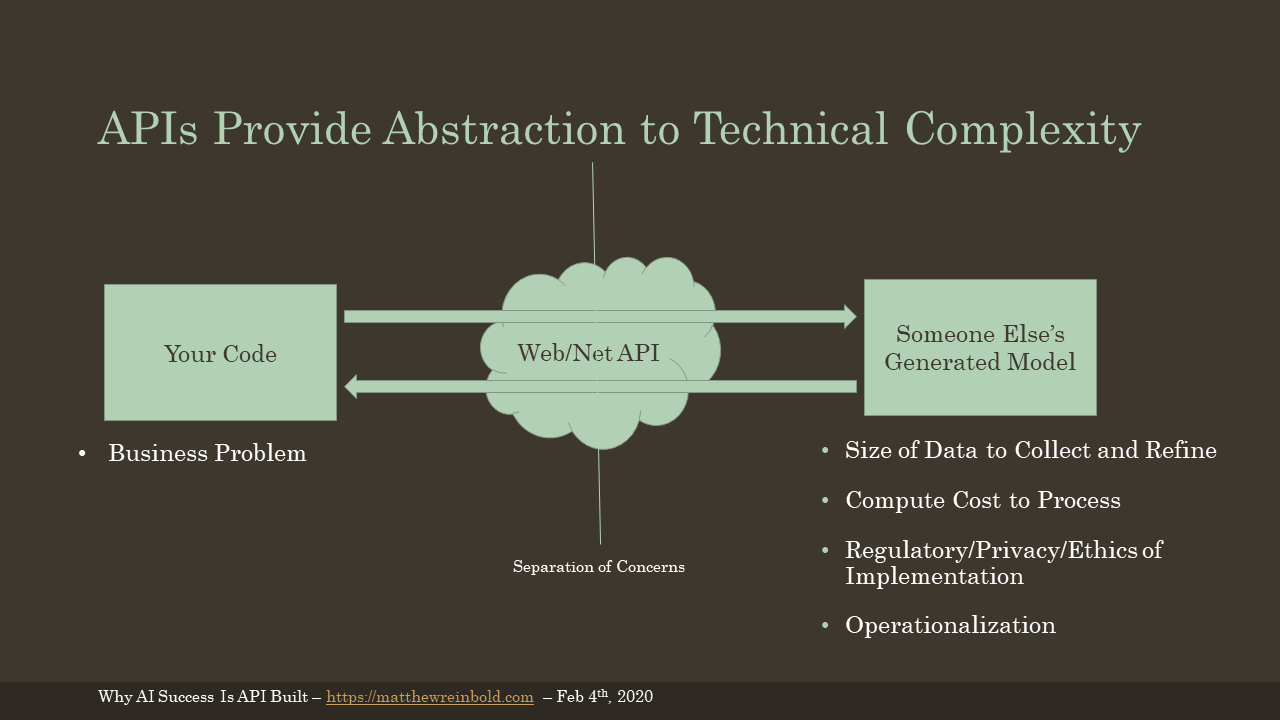
A web API (or Net API) provides a separation of concerns. You have your code. You focus on uniquely solving your business problem. Then, through an API, you consume someone else’s generated model.
The AI provider handles the tricky issues of:
- Collecting and Refining the Data
- Paying the electricity bill
- Fielding regulatory inquiries around privacy and security
- Managing the operationalization of data
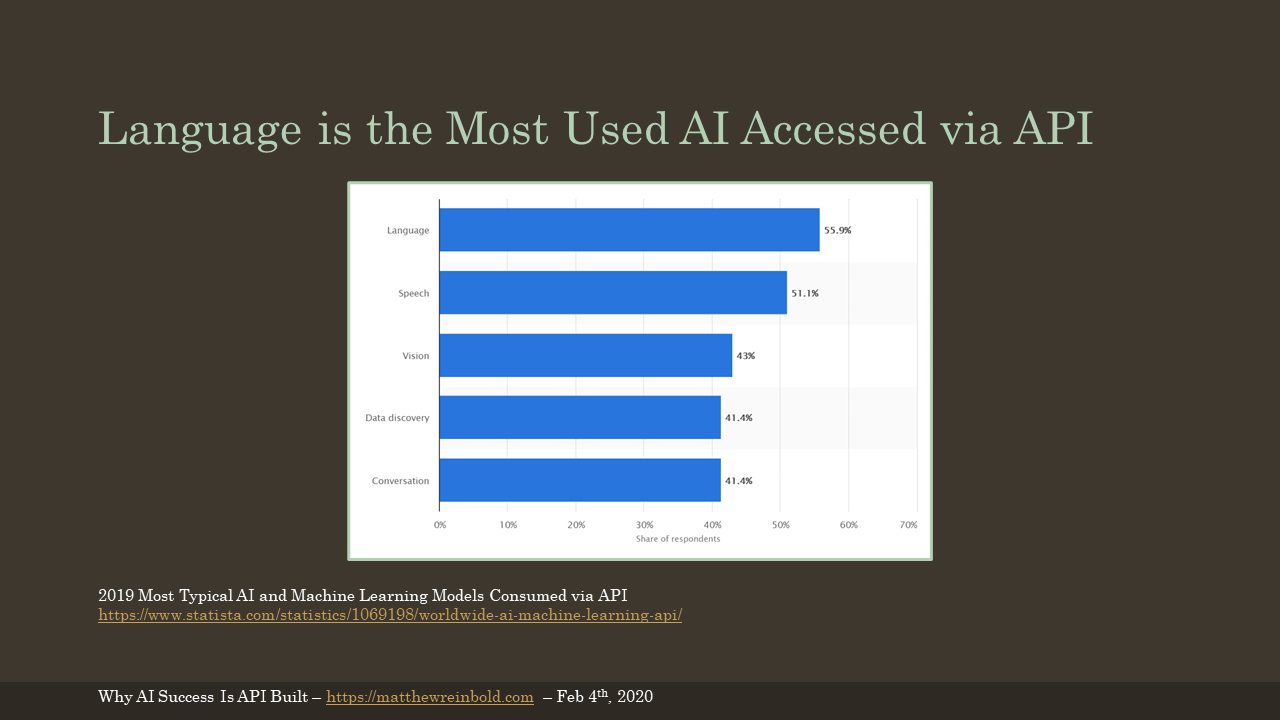
I see the industry already moving in this direction. The chart shown was created from a survey of which types of functionality were consumed via API. Things like natural language processing are highest on the list, for the reasons that Princeton’s Arvind Narayan pointed out: these are all perception related. Scaling perception is where AI has proven its usefulness and we’re moving toward a commodification of the feature.
(Chart from Statista.com)

When choosing between AI offerings via an API, it will be necessary for consumers to evaluate their claims via intelligent questions.
Vicki Boykis is a data scientist and writer out of Philadelphia. In her essay, “Neural nets are just people all the way down”, Vicki highlights some important revelations on one highly-touted AI use case:
“if you’re doing image recognition in 2019, it’s highly likely you’re using an image recognition systems built by images tagged by people using Mechanical Turk in 2007 that sit on top of language classification systems built by graduate students prowling newspaper clippings in the 1960s.”
There’s so much we should be asking about our AI providers. However, briefly, consider the incentives. Be wary if there are financial incentives to be less than transparent about how the model is generated or where the data is collected from. Also, be skeptical if an AI product also happens to use the latest blockchain-enabled, agile-Kubernetes, nano-service hype salad. Leverage others’ work, like this article comparing cloud providers; not all pieces are this comprehensive, but there are folks out there that are sharing their results for the community’s benefit. And, finally, interrogate the data. In general, we’re not good at this, in general, but, going-forward it will increasingly be more important.
Articles pictured in this slide include:
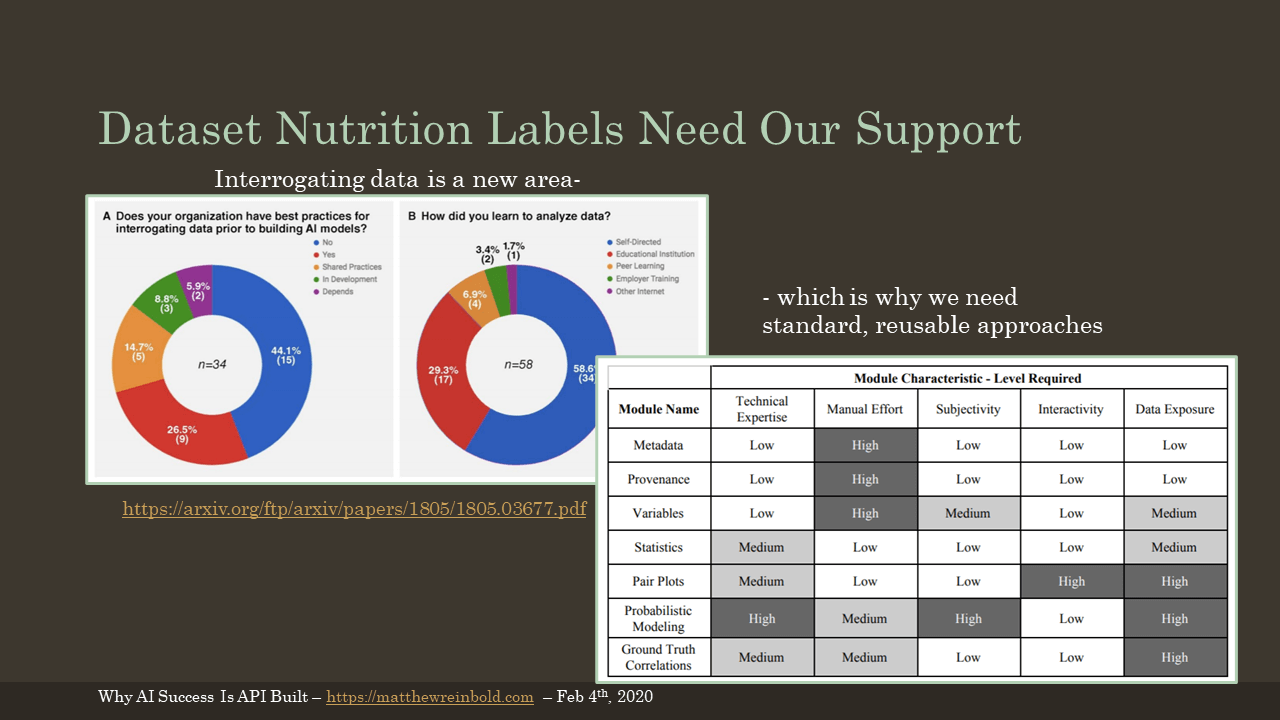
A survey was done asking folks whether they had practices in place to determine whether their data was good. Unfortunately, 44% said ‘no’.
Increasingly, that is not going to be an acceptable answer. We need to figure out best practices to interrogate the data. This is especially true of APIs since we may not have our hands on that data.
From the same survey, a majority of respondents reported that their ability to analyze data was self-taught. Going forward, we will need standardized, reusable approaches to create standardized, predictable results. As proposed in the linked white paper, one idea is using a nutritional label-like representation to compare and contrast datasets used in AI products.
Adopting a dataset nutrition label could help. However, keep in mind that having a robust understanding of the data is only one part of the process necessary to create a working model.
(Charts from The Dataset Nutrition Label Whitepaper)

That was a lot and, again, I’m only showing the tip of the iceberg.

If you are interested in learning more, there are numerous placed to get started. In addition to the many papers, presentations, and courses that I’ve linked to throughout this talk, I would also recommend the following books:
- You Look Like a Thing and I Love You by Janelle Shane
- A Human’s Guide to Machine Intelligence by Kartik Hosanagar
- Rebooting AI by Gary Marcus and Ernest Davies
In addition, I would highly encourage those working in the space to have a firm grasp of how these algorithmic approaches can cause harm. For that, I would suggest:
- Weapons of Math Destruction by Cathy O’Neil
- Automating Inequality by Virginia Eubanks
It also surprises me that there aren’t more sites that allow prospective AI users do “comparison shopping” across the major providers. Algorithmia used to be an online marketplace for algorithms. Similarly, Inten.to used to allow running sample queries across cloud algorithms. Both appear to have since pivoted. Certain AI APIs can still be found within the Programmable Web directory, however.
There are also a couple good sources for data, if people are looking for raw ingredients to get started. If you are aware of other sites that provide a similar service, let me know.

Thank you for your time and attention. My name is Matthew Reinbold and you can find me online at these fine establishments.
Good night.


