

While AI may be new(ish) for enterprises, the cultural transformation challenges are not. Seeing history repeat, I put high-level roadmap for business leadership and implementing developers on the change that is happening, the challenges, and what successful town planning of this new space looks like.
I’d like thank Dan Caton, and the folks at Tential Tuesdays, as being the catalyst for putting my jumbled thoughts, suspicious, and experience to words on this topic. Presenting at an event with a DJ was also a first. That’s some top-notch hospitality, right there.
I’ll also enshrine to the internet archive a heartfelt thank you to Vicki Boykin. She is a data scientist and the author of the excellent Normcore Tech email newsletter. Vicki was kind enough to provide a health dose of context to my more tenuous connections. Thank you, Vicki.
Now, onto the show.

Photo by Matt Noble on Unsplash.

In this talk I am going to cover:
- Why this is a critical juncture for a particular type of AI, called machine learning, in business
- List where machine learning application creates risk
- Present a roadmap for the ground that should be covered by a company’s AI governance program
- Briefly discuss how to get started, and who should do it

My name is Matthew Reinbold and, for the past half-decade, I have helped multiple fortune 500 companies create more fair, equitable, and empowered knowledge communities. I create software governance that empowers digital transformation. I’ve found myself situated a unique intersection of business strategy, distributed architecture, and internal developer evangelism.
I started my career building developer communities of practice. I also continue to do a fair amount with APIs. In addition to blogging at my website, https://matthewreinbold.com, I write an email newsletter called Net API Notes. I curate a list of in-person events for API folks at Web API Events and wholesomely Tweet.
Between 60-80% of software transformation efforts fail. With my help, however, Capital One embraced an API platform concept, going from zero to 3.5 billion daily messages passed. My team and I did this while maintaining design consistency and cohesion, maximizing lifetime ROI and minimizing risk.
After creating a thriving culture of APIs at Capital One, I generalized my approach for any digital modernization effort within an enterprise. As I assess upcoming challenges successfully building a data-driven culture, one in which machine learning can thrive, is a big one.

Simon Wardley is a researcher for the Leading Edge Forum. He popularized the concept of Pioneers, Settlers, and Town Planners. It is a way of thinking about technology adoption within a company. Briefly:
- Pioneers, as the name implies, discover uncharted territory. Their work is precarious, and they take numerous wrong turns along the way. This is deep research, hard to explain, and harder to understand. However, this is the work that leapfrogs what is possible.
- Settlers follow the pioneers, taking chance encounters and precipitous routes and creating repeatable, predictable certainty. They turn prototypes into products and products into profits.
- Finally, Town Planners take what is settled and grow it. They scale communities and provide the stable launching points for the next group of pioneers.
The wild west of high-end research labs is giving way to the more humdrum of daily application and tedious ROI discussions. And that transition is causing some discomfort.
Photo by Eniko Polgar on Unsplash.
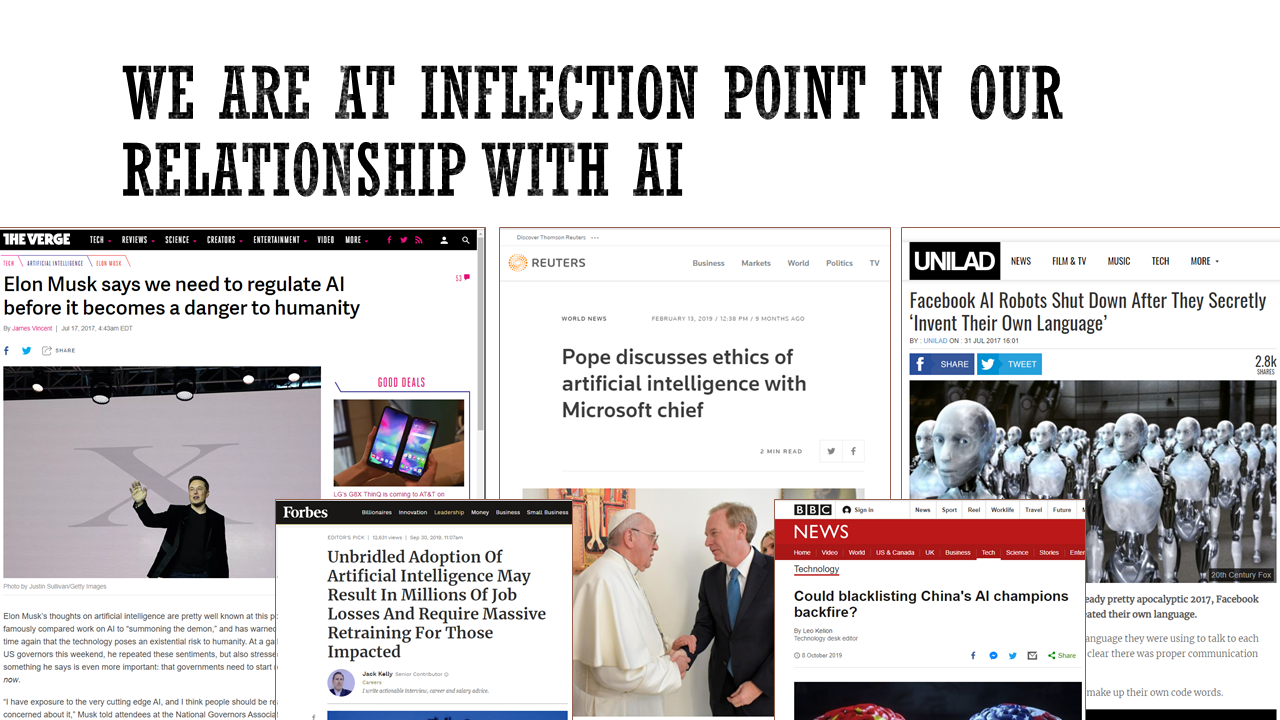
Anytime you combine immense potential, technical complexity, and cultural discomfort, you end up with headlines like these. It is telling when my 91-year-old Grandfather’s is scared about AI destroying mankind, due to the technical nihilism in his daily reading. Whether it is Elon Musk declaring the end of humanity or the Pope discussing Clippy’s mental state, many pixels have been burned hypothesizing the wild west we’re in.
There’s anxiety we’re on the verge of losing control.

Before I can talk about practical, town planner solutions, I first need to ground our conversation. That means addressing the ad-driven, click-bait hysteria around AI.
No, Skynet and Terminator-style robots are not imminent. The kind of general-purpose AI that we would recognize as “intelligent”, capable of comprehension and not just pattern matching, is still a significant way off. I highly recommend the book, shown here, by Gary Marcus and Ernest Davis. In “Rebooting AI”, the authors do an excellent job pointing out where hyperbole has outstripped h-indexes.
If you don’t have time for a book, Kevin Kelly posits some of the same arguments in his 2017 article, “The Myth of Superhuman AI”. There’s also the IEEE’s article, ‘3 Easy Ways to Evaluate AI Claims’.
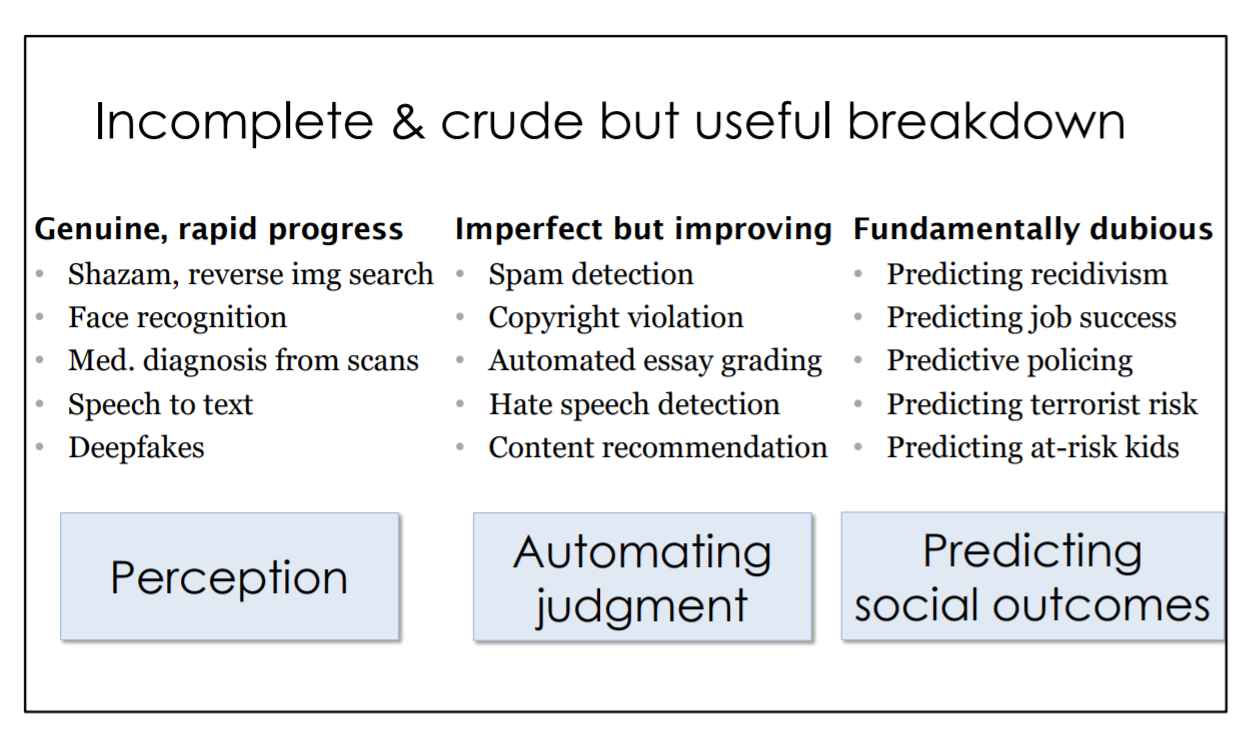
Princeton’s Arvind Narayan also published a wonderful talk entitled “How to Recognize AI Snake Oil”. I’ll leave exploring the entire piece as an exercise for the audience. However, I will steal his slide.
Arvind correctly identifies that AI used in the pursuit of perception and classification is getting better, and useful in a number of business contexts. Where there is trouble is when companies conflate classification with predicting social outcomes.

Machine learning is a form of narrow AI, one which uses statistics to find patterns in data. The reason we’re feeling the impact in the areas of perception and classification now is because of the:
- Greater ability to collect, store, and study data
- Increased comfort utilizing and scaling cloud compute
- Recent breakthroughs creation and tuning of neural networks
Companies need to be data-driven to compete in an increasingly fast-paced, complex market successfully. According to an Accenture global research survey, 85% of business leaders expect AI to open up new products, services, business models and markets, while 78% expect AI to disrupt their industry in the next 10 years.
Further, companies that are first to harness and apply data to business processes will experience what is known in systems design as a “reinforcing loop”. Data will create machine learning models, which will have business outcomes that can be measured, which will produce more data, etc. The first companies that implement this loop will have compounding competitive advantages. First mover advantage, here, means sustained leads for as long as the competitive landscape remains the same.
While the need may be obvious, however, fulfilling this vision is hard. According to NewVantage, seventy-seven percent of companies surveyed report problems adopting big data initiatives.
Further, from the same research:
- 72% of survey participants report that they have yet to forge a data culture
- 69% report that they have not created a data-driven organization
- 53% state that they are not yet treating data as a business asset
- 52% admit that they are not competing on data and analytics.
Put another way: pioneers discovered a new place, the settlers demonstrated value, but most haven’t found the town planners to scale this practice.
Creating a data-driven culture, one that can feed machine learning, is difficult. Many will fail.
Many will attempt the transformation. However, deferring all responsibility for ‘correctness’ to practitioners will result in as many definitions of ‘correct’ as their are people in the org. Companies need to think more holistically about how they approach AI in general, and machine learning, specifically.
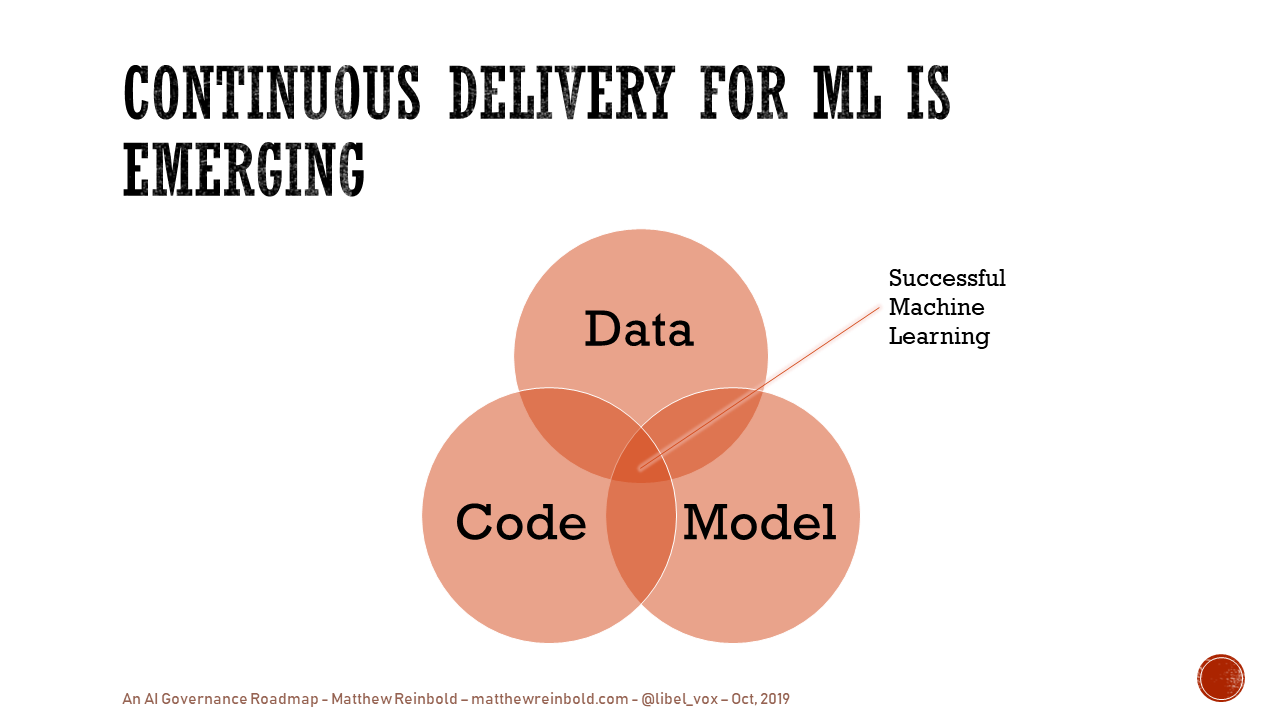
Just managing the assets used to create a model, for example, is challenging. A successful machine learning model is data, model, and code. As a research paper from Google points out, technical debt in these systems arises not from code complexity, but from data dependencies, model complexity, reproducibility, testing, monitoring, and dealing with changes in the external world. Further, a business should be able to release new models into production at any time. It may not be necessary to release all the time. However, the ability to do so means the decision becomes a business one, not a technical one.
We have well-understood processes for the continuous delivery of code into production environments; how shops apply automation, quality, and discipline to create repeatable and predictable outcomes. However, packaging and delivering the data, code, and model simultaneously is still an emergent area. See Martin Fowler’s website for more on continuous delivery for machine learning.
Creating a continuous delivery pipeline not just for code, but for data and models is difficult. There will be a lot of failures before we have this figured out.

And just as companies believe they understand the landscape they need to be successful in, they discover that the landscape is changing.
The last several years have demonstrated an increasing societal awareness of data and its impacts. A decade ago, ethics and fairness conversations happened, but they were limited, mostly, to policy wonk circles. Thankfully, that is not the case today and these are above-the-scroll topics for discussion; we are in a different place.
States, in response, are creating legislation like the California Consumer Privacy Act. Before that was the European General Data Protection Regulation, or GDPR. I’d wager we aren’t done with these yet, either.
Successfully navigating the growing regulatory regimes and changing societal moors is difficult. There will be some high profile failures (and even some unintended consequences, as we’re learning in light of the FTC COPPA fallout amount YouTube creators).
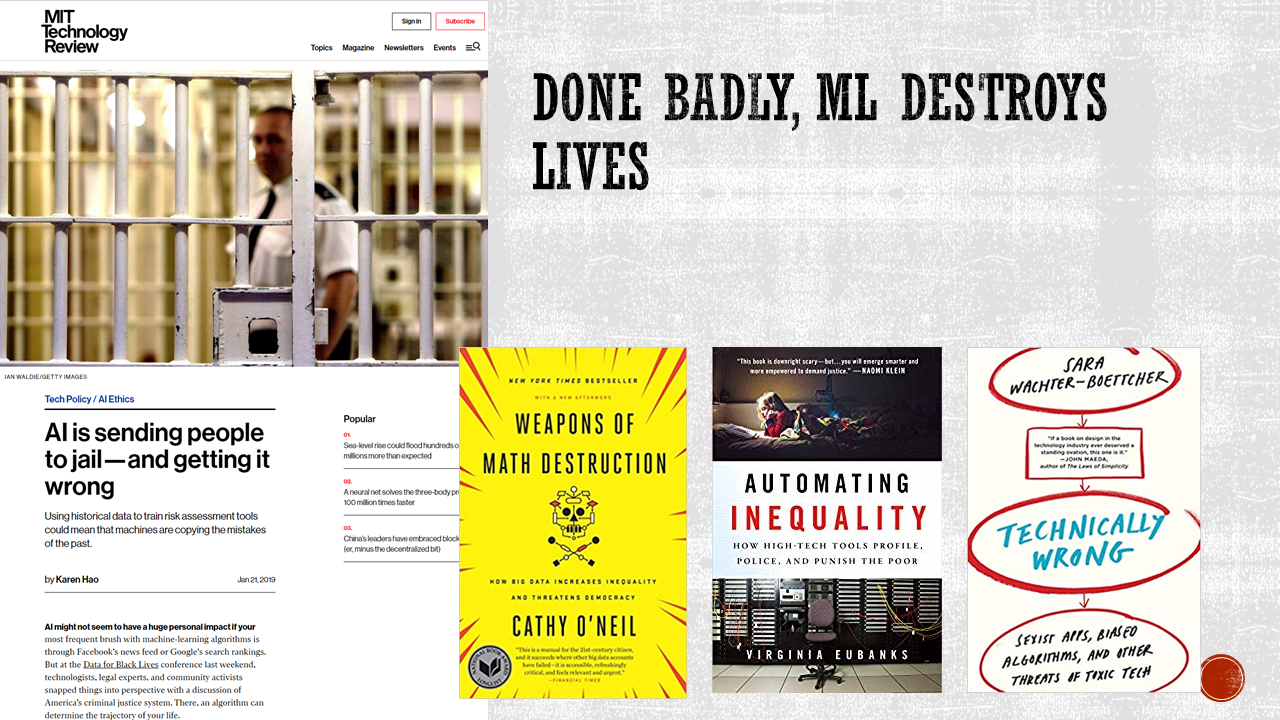
What does a machine learning model look like when it fails? Lost opportunities, unjust systems, and destroyed lives. Worst case, as described in the MIT Technology Review article, failed algorithmic decision making perpetuates societal ills. And it does so without clear “bad-guy” to detain and publish. Often, there is little to know accountability.
Many have written about algorithmic failure, at scale. For those interested, I’d recommend:
- Weapons of Math Destruction by Cathy O’Neil
- Automating Inequality by Virginia Eubanks
- Technically Wrong by Sara Wachter-Boettcher

That is all prior to predicting, policing, and preventing all the complex interactions, post-production, between systems machine learning practitioners might not even know about or control. Expecting engineers to be experts in all of these areas is unrealistic.
The challenges with AI are not just a “techie” problem. They’re not just an “analyst” problem. The complexity of this landscape is not something any single pioneer or settler is equipped to address. These problems are a company problem that requires a much broader and more systematic approach to fix.

Digital town planners are skilled at growing a complex system. These folks take their cues from urban planning, community organizing, and systems thinking. To solve complex emergent behaviors in software, they eschew causal, command-and-control approaches in favor of dynamic, community driven efforts.
So just hire some of these town planners, right? Or, better yet, just tell the folks on hand to start thinking like this and get back to regular work, right?
Photo by Arto Marttinen on Unsplash

If the potential is great and the challenges well known, then what do companies struggle with this? According to that NewVangage survey I cited earlier, executives state the problem isn’t related to the technology. Rather:
“Ninety-three percent of respondents identify people and process issues as the obstacle. Clearly, the difficulty of cultural change has been dramatically underestimated in these leading companies — 40.3% identify lack of organization alignment and 24% cite cultural resistance as the leading factors contributing to this lack of business adoption.”
IT governance is the people, processes, and tools deployed to ensure the effective and efficient use of technology to achieve business goals. AI governance, therefore, is a branch of IT governance to ensure the effective and efficient application of AI to achieve business goals.
Effective governance is more than being a bureaucratic gatekeeper, or a barrier between teams charged with delivery and the definition of done. AI governance must address the challenge of culture change. These town planners must bridge the wide world of threats and challenges with the domain expertise of the AI modeler.

A new AI governance program doesn’t have to invent guiding principles out of thin air. The good news is that there has been a tremendous amount of well-researched, nuanced work already crafted and available for free.
For example, Apple’s Security Principles require:
- Opt-in consent for the use of people’s data for training AI
- Employees, not contractors, to review and label samples used for ‘supervised learning’
Likewise, the NeurIPs conference encourages the declaration of critical components for reproducing a result be included with any work, including
- The number of models trained before the “best” one was selected
- The computing power used
- Links to code and dataset
The IEEE also has a book available describing a host of ethical considerations in autonomous and intelligent systems that is worth reading. Google, Microsoft, and AI Now (PDF) also have some great material available.

However, successful governance is more than just a checklist of things to do or not do. It must holistically address the entirety of a company’s transformational journey. These town planners shouldn’t just be sharing rules and approving forms. A community of practice can group their activity into three broad categories.
Understanding the Ecosystem
AI governance must understand the terrain they operate in; not only the dynamics that shape the landscapes within their own companies but industry and societal forces, as well. Success in this area requires:
- Building team amidst ambiguity, as there aren’t many maps for these territories
- Collaborating across functional boundaries
- Understanding the interplay between technology, business strategy, and ethics
- Identifying where AI has outsized impact on people’s lives
Helping Teams Navigate the Terrain
Once the landscape is understood, governance must help their fellow employees cross, safely and efficiently. This crossing might include:
- Introductory training across the entire company about AI’s importance to the company’s strategy, what it is, and how they can contribute
- Gathering, like an anthropologist, the experience and best practices of people already practicing responsible AI to codify and redistribute
- Empathetic listening to the fears and concerns at all levels, and carving the feedback channels back to those best able to take action
Audit/Measurement
With the list of critical, impactful areas where AI is making a decision, it is then important to have regular, ongoing audit to prevent failures and test fitness. Areas include:
- Inputs, like data quality and potential bias in training data
- Model(s), including statistical tests for model fit (overfitting, causation versus correlation), model transparency (interpretable), and stress testing against simulated data
- Outputs, listing decisions with explanations, and possible outliers
In this area, I see a future, emergent discipline. It would be one part data scientist, but another part ethical hacker. They would be familiar enough with the science to understand where the edges of a model begin to break down; things like how poisoning just 0.025% of the data can have a machine learning system misclassify the target. This new job title would stress assumptions made by others.

Those are broad categories of things governance could do. However, what might that include, tactically?
Resolving Tensions
An AI Governance group could be called upon when two values, seemingly, conflict. An example would be in a business attempting to create a model for personalized recommendations. Promoting tantalizing, or outright salacious, content might increase the total amount of time users engage on site. However, what if constitutes tantalizing to one group is scandalous in others? Setting the lines here requires clarity and consensus on ethical concepts, and well-understood means for the resolution of these tensions.
A whitepaper from the Nuffield Foundation explore these challenges in more detail.
Defining What Constitutes a ‘Critical Decision’
Factors for determining which algorithmic functions have greater risk include:
- What kind of data was used?
- What variables were considered?
- Global and/or local interpretability
Setting Environmental Impact Targets
MIT recently published an article claiming that ‘training a single AI model can emit as much carbon as five automobiles over their entire lifetimes’; this includes even the energy used to manufacture the car itself.
If a simple linear regression has slightly less performance, could it still be more desirable than an energy-intensive model generation? Who makes the call with whether melting the polar ice caps is an acceptable use of energy?
Update 2019-12-13 This recent NeurIPSConf paper makes the case for energy use accounting be a standard part of AI accontability.
Update 2020-01-28 Actionable steps for machine learning researchers should take to reduce carbon emissions include:
- Quantifying current output
- Choosing cloud providers and data center locations wisely
- Reduce wasted resources through effecient algorithms, good tests, and early debugging
- Choosing more effecient hardware
Defining Creepy
Yes, it is necessary to analyze data and machine learning for impropriety. However, that’s not the only factor at play. Designing AI-driven experiences require an understanding of where people accept machine intervention, and where people perceive a line is crossed.
As discussed in his book, “A Human’s Guide to Machine Intelligence”, author Kartik Hosanagar describes how people may fully embrace algorithms for things like automatic stock management (Betterment). However, they abhor automated systems in things like self-driving cars (Tesla). Why do we trust algorithms in some cases, but not in others?
One theory is that we’re happy to turn an algorithm onto a job previously performed by someone else (picking stocks) but not something performed by us (driving). While studies consistently show that algorithms may outperform humans, on average, we continue to believe that we are better than average (psychologists refer to this as the “better than average” effect).
It is not a matter of “what’s at stake”. People happily board planes everyday. Airplanes have been mostly algorithmically driven for some time. Yet, somehow, cars remain a bridge too far.
Creating a capable technology and having that technology accepted by an audience is two different things. Having a group that can identify these issues ahead of a costly deployment, and mitigate them will be important for successful adoption.

Nobody sets out to make an evil AI. I genuinely believe that the majority of people want to ‘do the right thing’. However, defining “right” and nudging people, as described in this 2019 Havard Business Review article, may not be enough; an enterprise’s best efforts may be perceived as patronizing or subtly manipulative.
This is a particular problem for AI practitioners because they possess three common traits:
- A strong sense of purpose
- A desire for autonomy
- A commitment to mastery
Nudges, to these highly trained professionals, may be perceived as threats to their autonomy or questioning their professional mastery.
As a result, it is imperative that any AI governance nudge be accompanied by:
- Transparency of Purpose
- Co-Creation of Content
- Constructive Framing (not just avoiding mistakes, but championing professional ideals)

This effective AI governance, ironically, starts with people.
Maybe I’ve convinced some of you to take the next step. Or I’ve suggested issues would be best solved collaboratively in your organization, rather than ad-hoc on a team-by-team basis.
Despite this, getting started isn’t clear. Perhaps you feel that you’re “just a developer”. Maybe you assume that you need to be in upper management to create the kind of impact that I’m talking about.
The massive changes in how organizations create software in the preceding decade are directly the result of bottom-up initiatives. Whether extending experiences and capabilities to the phone, adopting responsiveness through agile and continuous integration, or growing resiliency and ability to scale with the cloud, developers have been instrumental in defining the future of their workplaces. Yet, when it comes to something like how to relate to each other, or how we govern this new area, we hesitate. Or worse, we declare it “not my job”.
If you are interested in leveraging the power of machine learning in a just and fair way, and you’re not in a position to issue top-down edicts, there’s still a tremendous amount you can do. Begin identifying those people in your organization using these tools. Begin having conversations and identifying common points of both practice and pain.
Begin down the path of building a community of practice. If one does not exist, create one. Start with a Slack channel and grow from there. Begin building the momentum to create a demonstrable case to leadership for the need. Don’t wait for someone to get hurt shooting from the hip, wild-west style. Apply the type of town planner approaches appropriate for this new place.
Photo by Jehyun Sung on Unsplash

Photo by Zac Ong on Unsplash


