
Here are the slides and script for the presentation I made on July 17th at the San Francisco APIDays Conference. The theme for the event was ‘The New API Stack’.
This presentation is part of my goal to produce six original works in six months. For more information see the post about my conversion of travel time to productive time in 2019.
Without further ado, here is the talk.
Update 2019-08-13
The video recording for the talk has been released. If you’d prefer to watch rather than read, I’ve embedded it below.

Welcome, everyone. My name is Matthew Reinbold, and my talk this morning is how to overcome complexity with the principle of least power.
Photo by Shahadat Shemul on Unsplash

Modern software architecture is complex. John Ousterhout, in his book “A Philosophy of Software Design”, defines complexity as:
“anything related to the structure of a software system that makes it hard to understand and modify the system.”
In other words, a barrier to the kind of business agility that we crave, that is desired to win in competitive marketplaces, is how hard our architectures are to grok.

Complexity is a problem that we all share. Clear back in the innocent, carefree days of 2011 Marc Andreessen quipped that “software was eating the world”. That same year Forbes declared that “every company is a software company”. Sometime around the middle of this decade, our community began talking about how “APIs were eating software”.
As the Director for the Capital One Center of Excellence, I lead the team that sets the API and event streaming standards for 9,000 geographically disbursed developers. A vast majority contribute to the thousands of in-production, internal APIs that our company uses to deliver new products and experiences. My team and I oversee an internal ecosystem that delivers 3.5 billion API requests a day.
In addition to that “day job”, I also write an email newsletter called “Net API Notes”. There, I love to highlight stories of how other companies are managing their API journeys. While many are at different points along the road, all of us eventually run into same problem: complexity.

Why APIs? Because the API is the greatest leverage point in a complex system. An API is a means of abstracting complexity and hiding it behind an interface.
That abstraction allows programmers to work on a system without being exposed to all a system’s complexity at once. An API is a simplified view which omits unimportant details. It makes it easier for us to think about and manipulate complex things.
It’s why APIs have exploded, both internally and externally. In our organization, we might have started with APIs - either our own or 3rd parties - for critical functionality. However, in time, patterns emerged to deal with the complexity of the environment. If you’re Netflix’s Daniel Jacobson, you call these “experience APIs” (2014). If you’re Phil Calçado, director at Meetup, this is the Backend-for-Frontend (or BFF) pattern (2015).
At the same time that this orchestration API layering was taking place, James Lewis and Martin Fowler were talking about an abstraction they saw called microservices (2014).
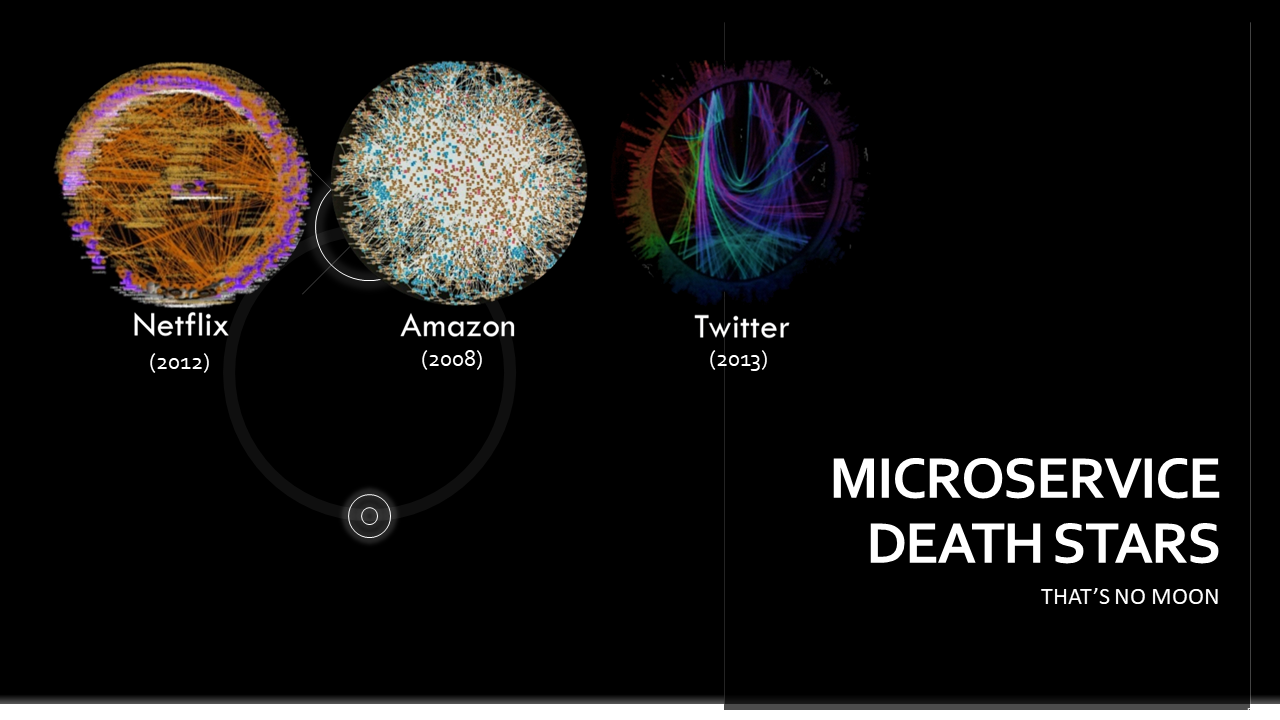
Thing is, complexity is neither creator or destroyed, is just changes shape. Not only are there more services, resulting in the infamous “microservice death star” style graphs, but the complexity introduced to try and manage these services – deployment pipelines, service meshes, monitoring tools, auditing, dependency managements also introduce their own emergent behavior.
In fact, over the past several years, through the writing on Net API Notes, I’ve seen a number of pieces where companies retreat back to a monolith exactly because they were more comfortable with the complexity that they had known rather than the new form it had taken.
With enough abstractions, we begin to see that layers change at different rates.
Images from “An Open Source Benchmark Suite for Microservices”

Abstractions changing at different rates doesn’t just happen in software. Wherever there are people, we see a stratification among abstractions.
In his book, “The Clock of the Long Now”, Stewart Brand described “Pace Layers”. He identified layers with each layer building upon slower-moving layers beneath it.
At the bottom are those things that are the slowest to change. These are things of nature. As far as we know, the laws of physics haven’t changed. For example, the speed of light is constant.
Next up is the cultural layer. People are people. It’s why the stories of the Greeks and Romans still resonate with us today.
Above that is governance. Note that this is not governments (think democracy or populism).
Above that, moving at a faster clip, is infrastructure. These are things like our road systems, or the electrical or plumbing networks in this building.
Moving even faster that that is commerce or the rate at which new products, services, and experiences can be brought to a market.
Finally, at the top and moving with the greatest speed, is fashion.

One layer isn’t more important than another. It turns out that all layers are important for a well-functioning system. Each has its place. Imagine if something as important as foreign policy was being run on a whim? Or if innovation was only allowed to happen at the speed of bureaucratic consensus.
As Stewart says in his book:
“Fast learns, slow remembers. Fast proposes. Slow disposes. Fast is discontinuous and slow is continuous. Fast and slow informs slow and big by accrued innovation and occasional revolution and slow and big control slow and fast by constraint and constancy. Fast gets all our attention but slow has all the power.”

When it comes to web, or ‘net’, APIs I see similar stack that changes at different rates. I’ll insert my usual model disclaimer here: “all models are wrong, but some are useful”. I acknowledge this is incomplete, but this API Pace Layering model we’re about to walk through is useful for raising topics for discussion and illustrating insights about complexity (and where we attempt to hide it).
At the bottom, again, are the laws of nature. The speed of light sent between distributed systems is constant. Not a whole lot there likely to change soon.
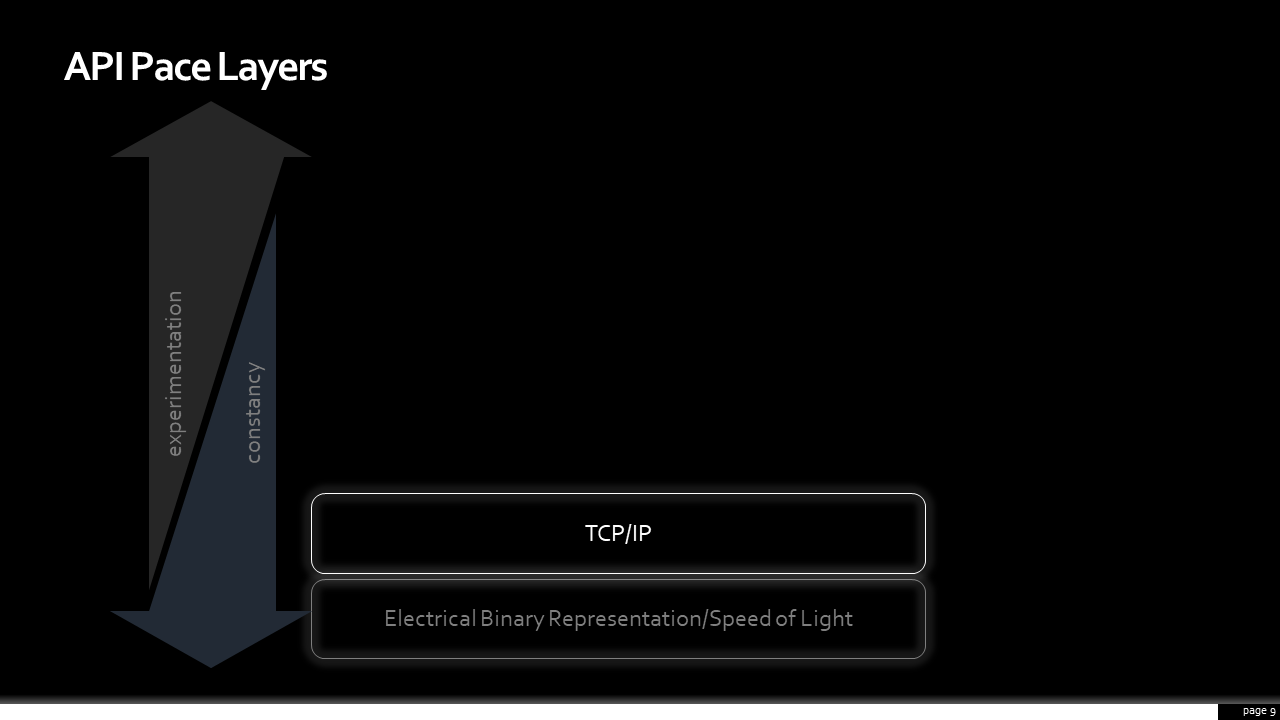
The next is the TCP layer. That protocol has been around since the 70s. That’s probably a good thing, as something as necessary as packet transmission needs to be stable; considering the amount of physical hardware, languages, and frameworks that have it “baked in”, you wouldn’t want it changing often.
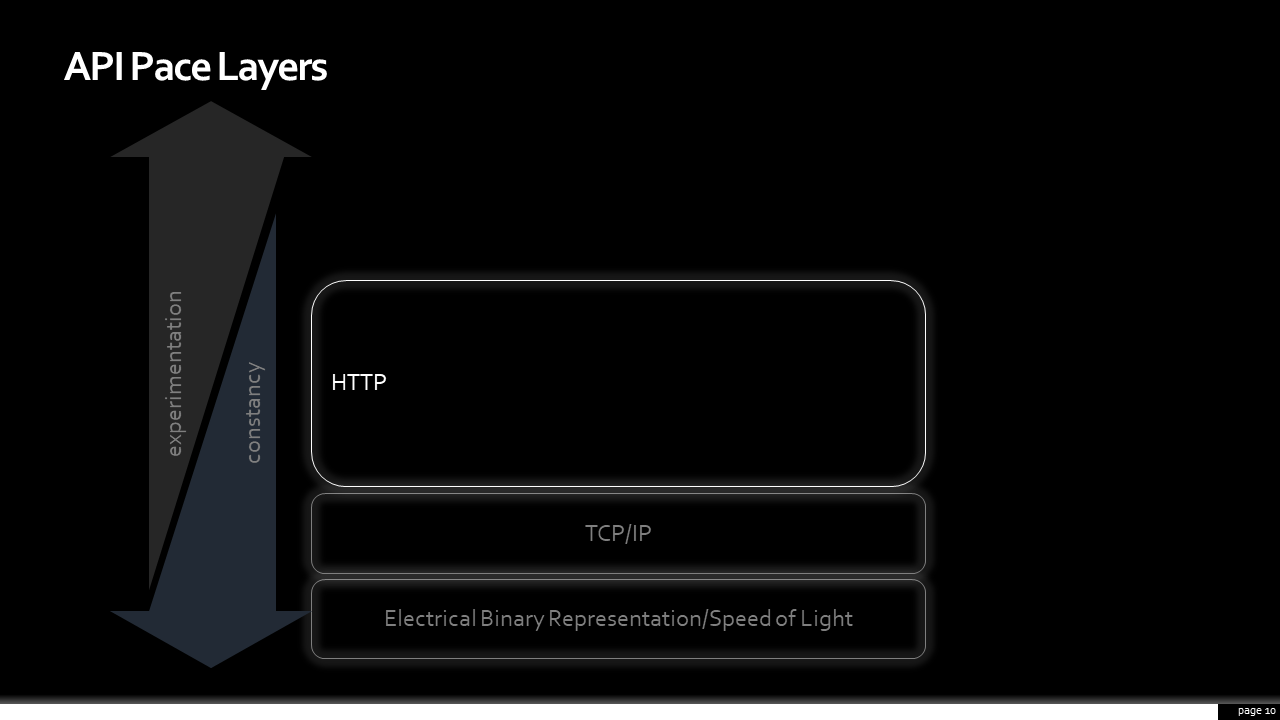
As we go up, remember that we’re beginning to pick up the rate of change. There are lots of protocols, like FTP or email. However, most of us in this room are probably familiar with HTTP. HTTP 1.1, which a guy named Roy Fielding worked on, was ratified in 1999. HTTP/2, which many haven’t implemented yet, was approved in 2015. It’s not whipsawing speed, by any stretch of the imagination. However, compared to TCP, it’s changing faster.

Here’s where I purposely made it interesting. HTTP, itself, is layered. There’s the verbs or methods. Everybody is familiar with “GET”, “PUT”, “POST”, and “DELETE”. Some might even use “PATCH”. There are others, like “OPTIONS” and “HEAD”, which are useful in other circumstances. There’s a couple more, but that’s mostly it; under ten items to recall that have been stable since the last millennium.
There are status codes; while, officially, there are 50-60 status codes the ones we care about can be broken into three broad groups. Any 2xx responses tell me, as a client, my request succeeded. Any 4xx tells me, as a client, that I need to modify my request before doing it again. Also, 5xx tells client me that the API provider is having a very bad moment. Again, stable, consistent, and doesn’t require me to introspect the payload for the high-level gist of what is going on.
The last layer of the HTTP protocol worth highlighting is headers. There are about a hundred of these. Some of them get into a fair amount of subtlety and nuance. Not all are that useful. However, this is where we get a wonderful set of tools to shape requests. The fastest request is the one you never have to make. If an API provides thoughtful clues through caching headers to a client, it is a beautiful, highly-performant, thing. Headers also where we can perform content negotiation, allowing the same API to return the JSON representation, a CVS file, a PDF, a binary image, or more all from the same resource.
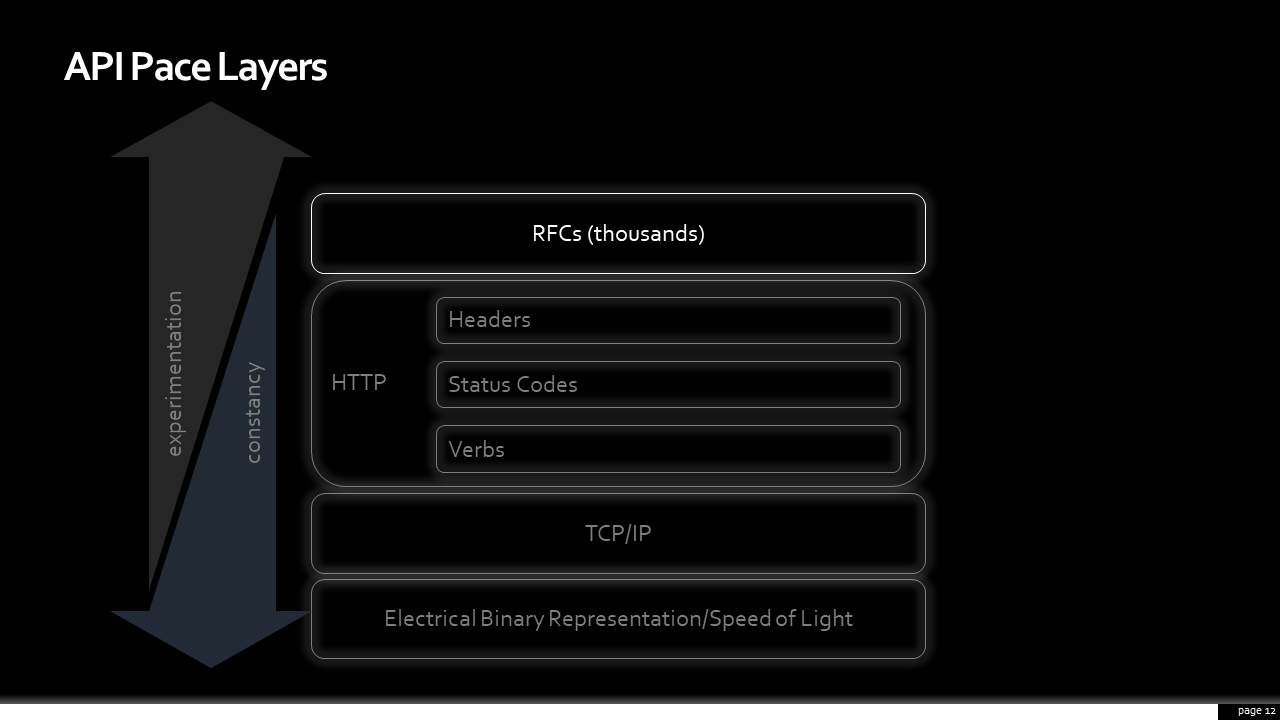
Above HTTP, evolving at a greater clip, are the IETF’s Requests for Comment, or RFCs. There are thousands of these notes which capture proposed ways communication on the internet might work. That’s a lot and there are new ones all the time.
There is some excellent work here that can powerfully aid comprehension and intuitiveness of a design. When things go wrong, RFC7807 defines a common error object. By using a standard, clients aren’t left having to figure out where in the payload to look for information to help solve their issues. A standard might also suggest information, or representations of information, that you might not otherwise have considered.
There’s also RFC 8594, the sunset HTTP header. It is a way of telling someone that requests a URI that it may become unresponsive in the future. This one was fun to watch being born, on Twitter and through email, by this extended community. A common need for better lifecycle management was identified folks online and they swarmed together to discuss merits of different approaches. From their efforts, we now have a abstraction: the complexity of having to come up with how to do this was handled by someone else.
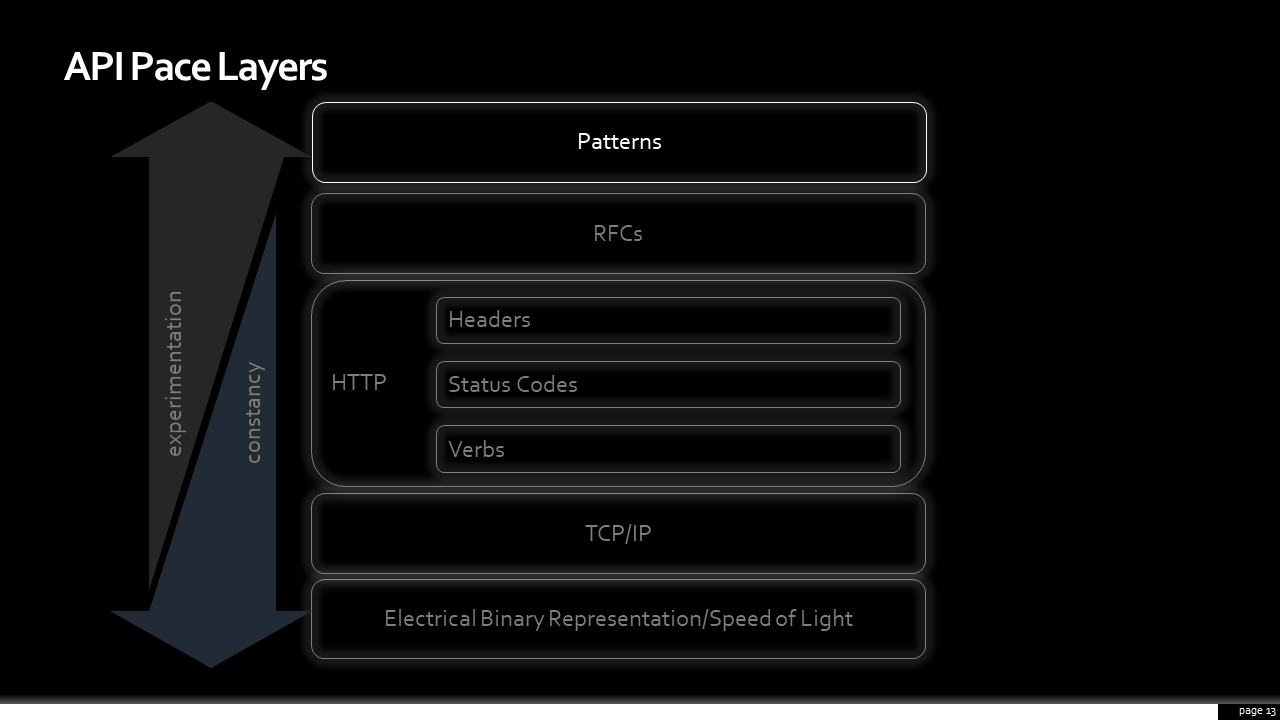
Finally, at the top of this layering, are patterns. There are some patterns, like the backend-for-frontend or experience API pattern, that become popular - possibly even so popular that they end up generating dedicated RFCs to support them. Remote Procedure Call (or RPC) is a pattern. Webhooks are a pattern. Hypermedia is also a pattern. These can are multitudinous, and a new one can be introduced as quickly as the Netflix engineering or Hacker News forums publish a new post. These are constantly changing. Some become quite fashionable.
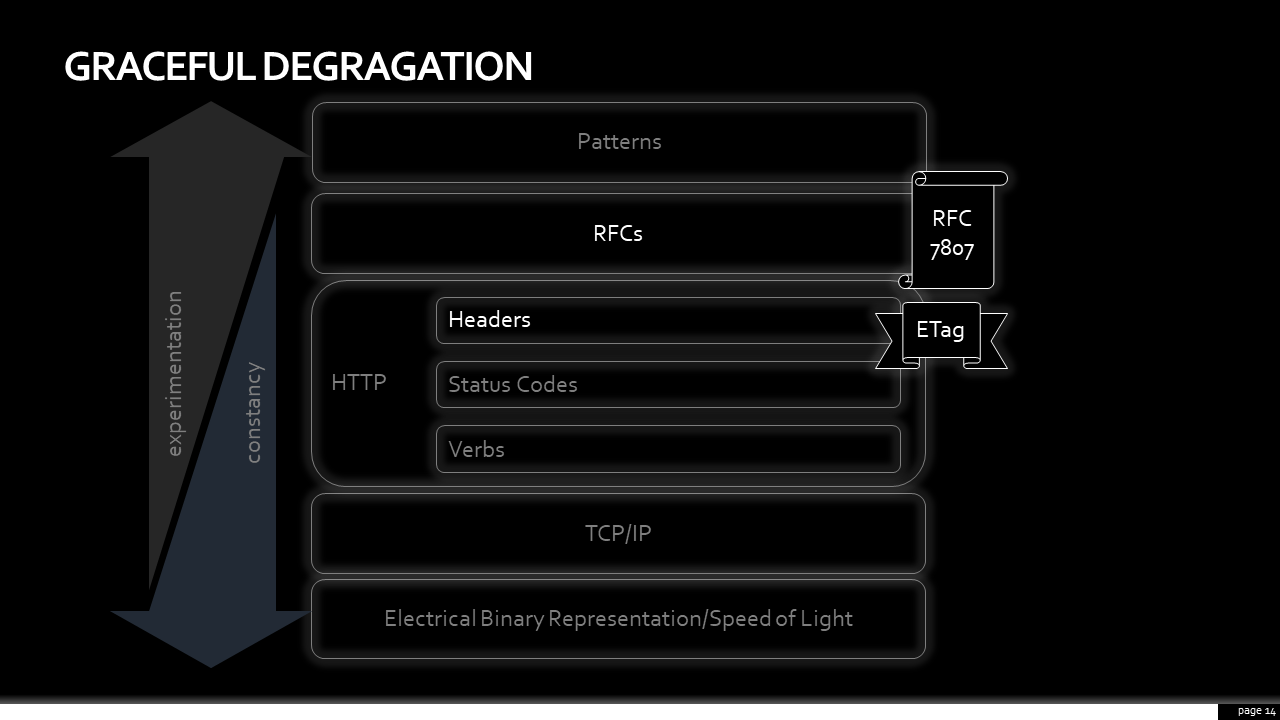
The wonderful thing about how these layers perform in a complex system is how they gracefully degrade. Suppose, for example, that I provide an API that implements an RFC, like the common error object. What if the client isn’t expecting, or doesn’t care that I’m following a prescribed standard. Do we fail to exchange meaningful information?
Of course not. A client unaware of RFC 7807 would only see a JSON response returned to them, and they would parse it anyway, the same as they would if my response was something that I came up with off the top of my head. The advantage are those complex ecosystems featured in the microservice death stars – when all services express information in the same way, it opens opportunities for tooling; tooling which takes the cognitive burden from developers, freeing them to focus on the business problem.
Let’s take another example and go a layer deeper. As an API provider, I have the best understanding of when the underlying data changes. As a result, I provide cachecontrol and ETag headers to the client, allowing them to make smart decisions about when to request an object. After all, the fastest API call is the one that didn’t have to happen in the first place. If a client is savvy and picks up on it, great! If not, things still work; maybe not as efficiently, maybe not as elegantly. However, building in layers that can gracefully degrade means that communication is still possible.
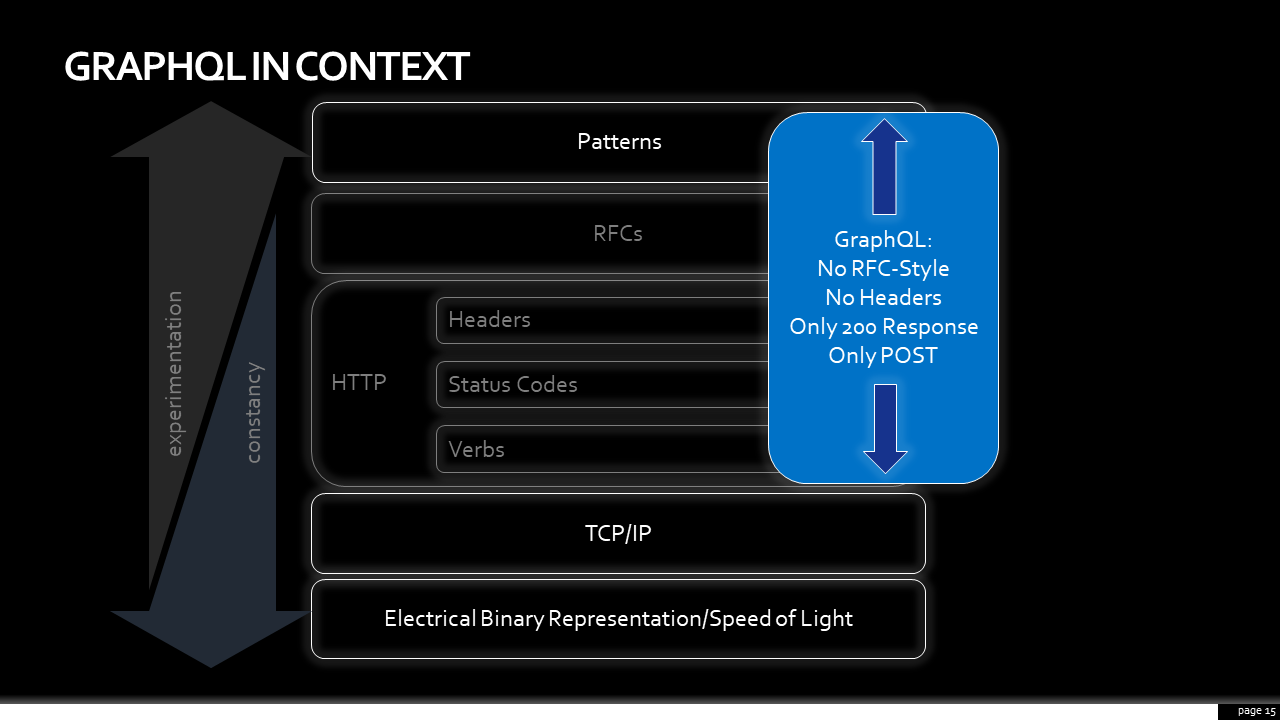
Now, for a brief moment, let’s talk about GraphQL (going through a similar exercise for gRPC is left to the reader). GraphQL is a query language for data retrieval and updating via HTTP. I put it in the “pattern” layer, as it is a different API interaction pattern between client and server.
Unlike the other patterns that I had previously mentioned, however, GraphQL is not built upon the same layered approach. All requests, be it data retrieval or mutations to update, are submitted via POST. The only status code ever returned is a 200, requiring introspection of the payload of every response in case there is an error embedded in it. Headers aren’t encouraged, as they’re not displayed in tooling like the explorer from GraphQLHub.com. There’s no equivalent RFC-like error response for GraphQL, although vendors like Apollo are promoting their approach.
There’s a paradox here. I can hear it. “Matthew,” you might say, “by freeing us from having to think about verbs or codes or headers or RFCs – by getting rid of the layers, aren’t we abstracting complexity behind a single abstraction?”
Remember, complexity is neither creator or destroyed, is just changes shape.
GraphQL is not a layered approach; everything from the pattern to the TCP/IP layer is either strictly specified by GraphQL or left for developers to recreate in their own, bespoke way. Eschewing layers, as GraphQL gives developers tremendous power to solve problems exactly how they imagine a problem to be solved; both from the consumer’s point of view, where they can tailor the response to their needs. The API provider also can implement their own approaches to common distributed systems problems. But that power comes with great complexity. The layers that abstracted the complexity of things like caching, of error handling, content negotiation are all left to the developer. And having each GraphQL solve those things in their own fashion will increase the complexity of comprehension on the part of clients and tool makers.

The principle, or rule, of least power states that one should:
“Choose the least powerful language suitable for a given purpose.”
That seems incredibly counter-intuitive. Don’t we want more power to solve problems? Shouldn’t we deserve the newest tools? The most flexible frameworks? Who in their right mind is a fan of the least among us?
We can apply this to our layers. When I call an API, I can include instructions as to whether I’m reading or updating information in the payload; that is a payload the server will have to introspect and act on. Or I can use the humble verb at the lowest layer, and signal the same thing via a GET or PATCH. It seems like a simple thing but it drastically affects where the complexity of our tracing, monitoring, entitling, securing, rate-limiting, framework-ing, and supporting goes.
Update: 2019-09-03
For a robust list of useful, defined elements that apply to a number of common use cases, check out Standards.REST. Why re-invent the wheel?

So do I hate GraphQL? Am I advocating that we should only use “boring” technology? That the old stuff is better?
While I am a fan of The Boring Technology Club, that is not the message. I’ve grown to appreciate what happens within the fashionable layers. The chaotic experimentation is exciting. The vigor for overturning assumptions and pursuing new avenues is how we discover new, potentially powerful ideas. In a healthy stack, the best ideas go from being fashionable, to products sold via commerce, to essential pieces of infrastructure eventually requiring governance and important pieces of business culture.
What I do advocate for, however, is conscious, decision being made when pursuing new patterns. Eschewing layers comes with trade-offs. Enter into those decisions with eyes wide open.
As Mythical Man Month author Fred Brooks said:
“There are no silver bullets.””
Photo by Mariya Georgieva on Unsplash

In conclusion, every company is a software company which means every company is wrestling with growing complexity.
One approach to dealing with complexity to create abstractions. The abstractions at the different layers in any system evolve at different rates, which is a good thing. Fast layers accrue innovation and occasionally incite a revolution while the slow provide stability and filtering.
Net APIs have evolved into different layers. Each layer provides a host of solutions to common problems that gracefully degrade if not used. The principle of least power suggests choosing simple, layered solutions to layer-spanning solutions.
Only by making more informed decisions, fully aware of the trade-offs at hand, will those responsible for API governance be able to overcome the complexity of our current API stacks.

I’ll have the slides, along with some additional color and links to sources, at my website, matthewreinbold.com. I’ll announce when its ready on my Twitter stream and in my newsletter, ‘Net API Notes’.
I am Twitter’s @libel_vox, and you can follow me and continue the conversation there. Thank you for the precious gift of your attention. Enjoy the rest of the conference!


