

First of all, thank you for being here. I hope you’re healthy and you’re safe, and those that you care about are secure as well. We’ll get through this. I’m sure of it, and someday we will see each other again in person. However, until then, thank goodness we have these kinds of arrangements to share and continue to learn from one another in some form.
This presentation is entitled “We wrote an API description, now what?”

In many organizations, OpenAPI has become the way to capture and share API intent and function. In API-Design-First shops, the creation of an OpenAPI description is required.
But after you’ve created this machine-parsable description, what is next? How do you get the most significant amount of ROI for the time and energy you invested in it? How are others using their OpenAPI artifacts beyond just documentation? And how do you get started? I’ll answer those questions and more in this talk.

My name is Matthew Reinbold, and I am Postman’s Director of API Ecosystems and Digital Transformation.
At Postman, I’m a member of the Open Technologies Program. Our mission is to improve API practice, education, and research for companies of all shapes and sizes.
In addition to that, I also write a weekly API email newsletter. The amount of API-related things published on the web can be overwhelming; Net API Notes started as my attempt to filter the signal from noise - it just turned out that the persistent act of sense-making was valuable to others as well. It also prepares me for conversations like the one we’ll have today.

First, though, let’s establish a few things. I’m not going to cover the history of how OpenAPI and AsyncAPI became nearly the defacto API specifications. There are plenty of other talks covering that ground in greater detail - some at this very conference!
However, I do want to clarify how I will use a couple phrases of throughout this presentation. If you use these words differently in your day-to-day work, that is completely fine. For this presentation, however, when I say API Specification, I refer to the specific documented, syntactical requirements an API designer writes to. Examples of API specifications include OpenAPI and AsyncAPI.
When I talk about an API Definition, I refer to the JSON or YAML document that captures your unique API’s business intent, written to meet a specification requirement.
Again, when I talk about an API specification, I talk about what a standards body writes. When I talk about an API definition, I am talking about what you write.
Also - in this presentation, I will be sharing or referencing numerous links. If you are interested in those links and don’t want to wait until this presentation is published on my website, go over Twitter and look up the username libel_vox, shown in the footer. All the links are in a Tweet pinned to my profile.

Let’s start by rewinding the clock.
Guido of Arezzo (ur-EH-zoe) was a Benedictine monk living in Italy at the turn of the millennium before last, around 1000 AD. And Guido had a standardized notation problem.
At the time, the pinnacle of popular music was liturgical chants. People went crazy for them. But as Guido visited churches, he noticed how much younger singers struggled to learn the songs.
It was common to have parchments with the words and some occasional squiggles that suggested the performer move their voice higher or lower. However, there was no representation of pitch.
Image source: original uploader was Robbot at Dutch Wikipedia. - Transferred from nl.wikipedia to Commons., Public Domain

The solution, Guido reasoned, was to invent a means that would allow someone to sing along even if they had never heard the music before.
So Guido invented the staff. With fixed notes and a specification for conveying them, young students could “better detect the level of pitch”, as Guido wrote.

People new to APIs also have trouble getting started. And API documentation is usually the first thing people think of when they think of what to do with an API description. Unfortunately, that’s often where it ends, too.
The image on the slide is a grossly simplified development process, but one that is all too common. In it, a bunch of work is done to create a thing and, when it is ready to “go live”, some documentation is made for “the customer”.
Don’t get me wrong - documentation made this way is better than a random PDF or CMS entry - both of those are akin to non-uniform random squiggles Guido’s students previously had. There are many places where you can insert an OpenAPI description and get out some beautifully rendered documentation, either for your dev portal or for sharing with a customer.
However, documenting at the end means that the context and nuance of why something is the way it is has to be recreated and reassembled. Because of this, things get left out. The API description, when treated this way, becomes lipstick on a pig.
If you’re composing music, one doesn’t wait until the entire song is done before writing something down. In the same way, we need to think about API descriptions as not something that comes at the end but a means at the center of creating a better result in multiple ways.
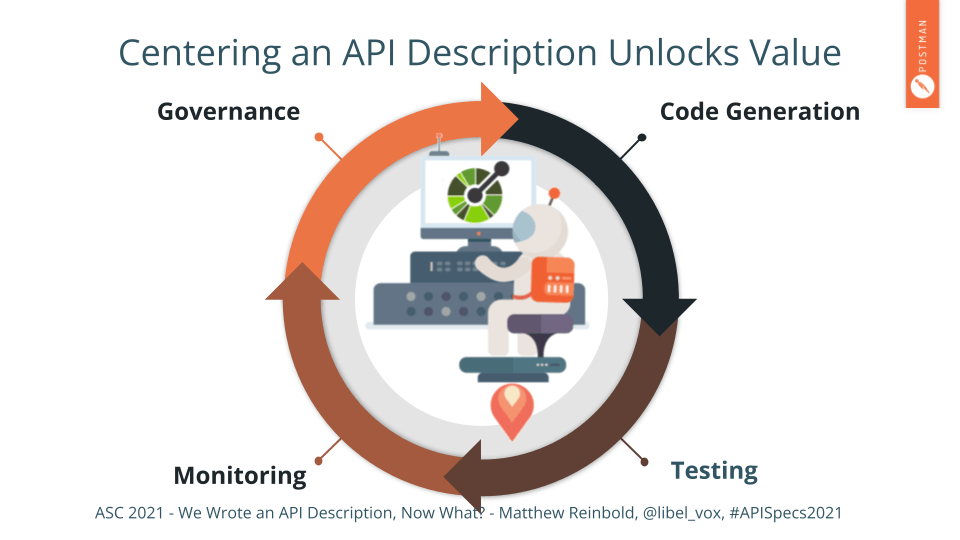
A standardized representation of intent, or an API description, can be used for more than documentation.
If we start treating our API description as our central source of truth about the API, rather than an afterthought or “nice-to-have” documentation, a whole host of options open up.
For the rest of this presentation, I am going to detail four areas:
- Code Generation
- Testing
- Monitoring
- Governance
After that, I’m going to extrapolate a bit.

First, let’s talk about code generation. If you have an API description, whether yours or an API you wish to consume, you are well on your way to having code generated for you.

There is no shortage of client code generators available. The Open-API generator supports an incredible number of programming languages. I had to make the type super, super tiny on this slide to fit them all in.
I’ll admit that generators won’t write everything. However, getting the tedious, non-differentiated boilerplate out of the way through generation is a huge time saver.

And it isn’t just client code! You can also stub out a server implementation if you have an OpenAPI description of how an API works.
In the slide, I have a picture of Postman’s interface. I’ve loaded an OpenAPI 3.0 description. Next to the YAML syntax, I have a button that allows me to create the beginnings of my server code with just a couple of clicks.
Servers include Go (Chi), NodeJS (Express), Java (JAX-RS), and Python (Flask). That is a compelling way to kickstart new development and the next logical step with what we can do with these API descriptions.

It is also possible to generate SDKs from OpenAPI descriptions.
One of the problems with SDKs is finding the team bandwidth to keep feature parity across multiple languages, especially during rapid change. Plaid has a fantastic case study detailing how they automatically keep a broad suite of beneficial SDKs in sync and up to date from their OpenAPI sources of truth.

But it’s not just code that we can generate. Let’s take it to the next level and talk about generating code to test code!

Testing an API is one of the most important things to do. However, not all testing is created equal.
At the bottom of this pyramid of testing needs, we need to make sure our response payload is as expected; making sure that when we make a request we get the response we intended in the shape expected.
Next up, we have chaining HTTP calls. Once we know that one request works the way we assume, we start using it in conjunction with other calls as part of more advanced workflows.
Moving upwards, we have data-driven requests. This level is where we take our static requests and begin to change the data provided. In doing so, we being discovering the rough edges and uncovering assumptions about ongoing usage.
Nearing the top are negative tests and error flows. In other words, at this level we’re purposely stepping off the “happy path” and evaluating how gracefully the API fails.
Finally, at the top of the pyramid, we have contract testing. Testing at this level is no longer about the API we’re creating but verifying the consistent behavior of other APIs we might be dependent on.
Like many pyramids, every level is sized in approximate proportion to how much effort should be expended. So, for example, companies should spend a large amount of effort verifying that the response payloads are structured correctly or at the bottommost level before moving upwards.
However, where people should put the bulk of their effort also happens to be some of the most tedious work. Therefore, it is a no-brainer that we leverage an API description to provide the necessary coverage.
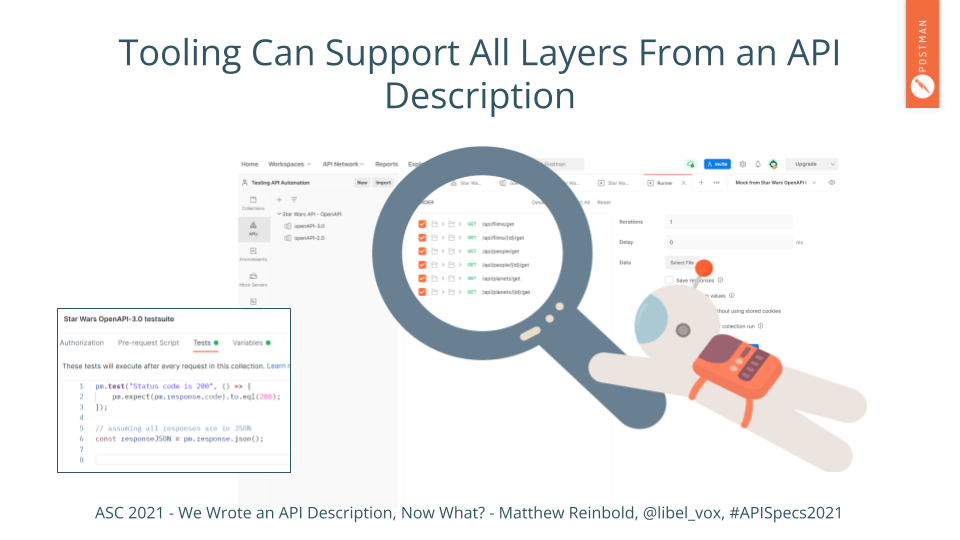
A valid OpenAPI document inside Postman can be used to create test cases to be run across multiple endpoints. Or you can customize on a per-endpoint basis. Like code generation, generating tests free brain cycles on solving higher-level, more challenging problems.
That generation is possible because we have a standardized notation that conveys our intent even if we haven’t seen the API before.

Things get really interesting when we take that code and tests that we previously created and connect it to automation. We are now able to aggregate and monitor a complex system. We can “see” not just individual APIs for the trees they are. Instead, monitoring whole collections of APIs gives us a sense of the larger forest.
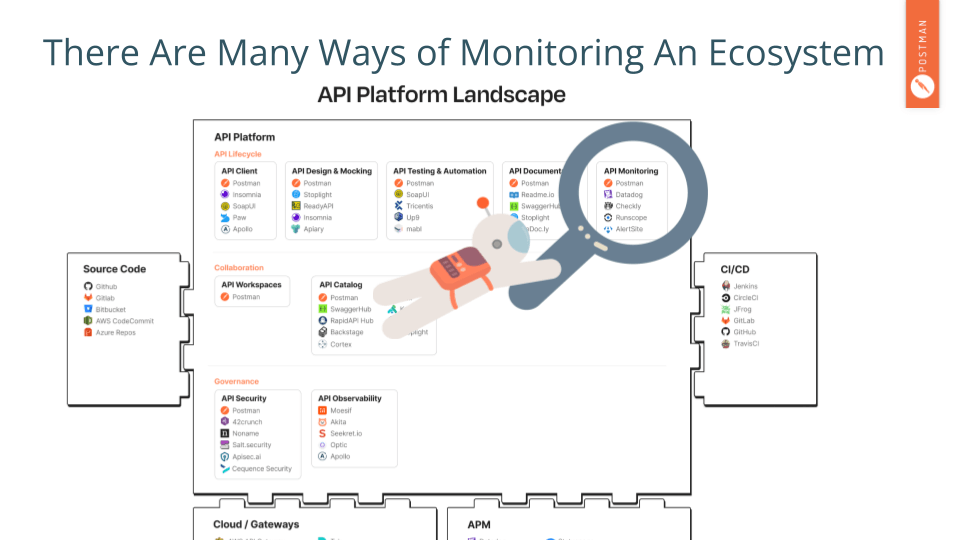
Recently, Postman’s founder, Abhinav, shared a vision of the API platform landscape. And there are many companies in that view that perform what we call API monitoring: using a remote computer to send requests to an API on a scheduled basis.
But ensuring that an API is running or not is the same thing we were doing a decade ago. It is important, but it also scratches the surface of the complex automation possible with API descriptions and some simple bridge code.
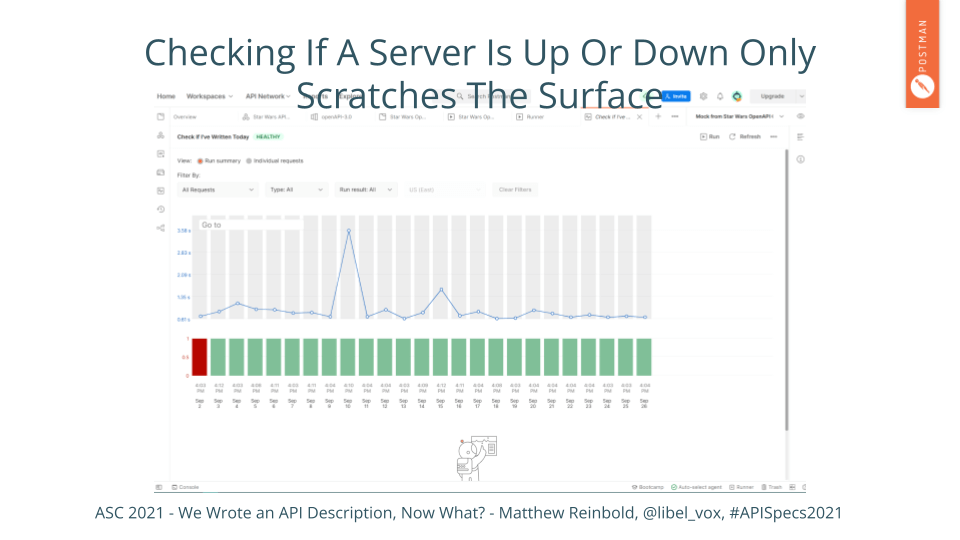
Many are familiar with the website, If-This-Then-That (IFTTT). With API descriptions, creating workflows via the Postman monitor is nearly as easy.
As I mentioned, the purpose of the Postman Open Technology Program is to elevate API practice across all industries. As you might imagine, that entails a lot of writing. Rather than just using a monitor to tell me whether services I care about are up or down, I created a workflow to prompt me to complete my writing.
I used an OpenAPI description to create a call to my cloud-hosted markdown editor. That gets me the words I’ve written so far daily. I put together some logic to not worry about weekends because the worst thing is stress-inducing notifications during recovery time. Finally, I merged that with the results from another OpenAPI description that gets and parses US holidays - again, alarms aren’t going off when I am recuperating.
It does require a bit more work than dragging lines between colorful chicklets (Rest In Peace, Yahoo! Pipes!). However, if you have standardized service representation, exciting workflow automation is at your fingertips. We’ve gone beyond just testing APIs to creating low-code solutions.
That’s empowering for the people in your organizations who may not be full-blown developers but still want to take advantage of information and services already available.

That brings us to governance.
An API journey doesn’t start with a cast of thousands. For most companies, their first API began as a targeted means to a specific business end. Scaling architectures, processes, training, and tooling was far from the minds of all involved at the onset, as it should be - a town doesn’t build its public works department when there are only a few homesteads.
However, with more people creating APIs more experiences, architectural styles, and bespoke infrastructure are introduced into the growing API ecosystem. In the absence of repeatable processes, preferred techniques, or uniform tooling, the results from API production will become unpredictable - coordination costs across unaligned pockets of practice increase along with inefficiency. Higher-order alignment suffers. As described in the book Accelerate, “teams become adrift, concentrated on micro-optimizations disconnected from aligned business delivery”.
Somebody needs to be concerned with those higher-order concerns and the health of the ecosystem. Many might assume that necessitates a cumbersome, gatekeeping API review. However, with API descriptions, there are several lightweight, helpful things we can do to encourage alignment while maintaining team autonomy.

To create consistency in approaches, many companies create API style guides. But just having a proposal of what people should do is not enough. Just because something is written down does not mean it will be interpreted and presented in an API description the same way.
In the slide, in gray, I have an example suggestion for pagination that you might find in a style guide. It encourages the developer to use the words “limit” and “offset” when giving callers the ability to page through a collection of items.
That may seem straightforward. However, what happens in practice is something akin to what appears on the left side of the slide, in purple. Yes, the author included the words “limit” and “offset”. But the articulation of how these two keywords are used is still vague. As a caller of this API, we may assume that both are numeric values with some certainty. However, several questions remain. Is there a maximum value for “limit”? Is offset 0-indexed? What is the default page size? Are these values to be passed only as query params, or do they also work as header values?
The API description on the left meets the letter of the law, but not the spirit; this API’s user has to spend additional time and energy to figure out how it works.
So should we berate an API designer, especially one new to the company, for not magically including all the additional verbiage of the right-hand example? OF COURSE NOT! “Just knowing” is hard. The style guide should make doing the right thing easy! Rather than leaving the right thing up to interpretation, the style guide should provide the desired YAML or JSON representations for anyone to copy and paste into their designs.
It sounds straightforward because it is! Creating meaningful templates and snippets that solve everyday problems creates alignment because you’ve made doing the right thing easy.
I’m written more about these approaches on my website.
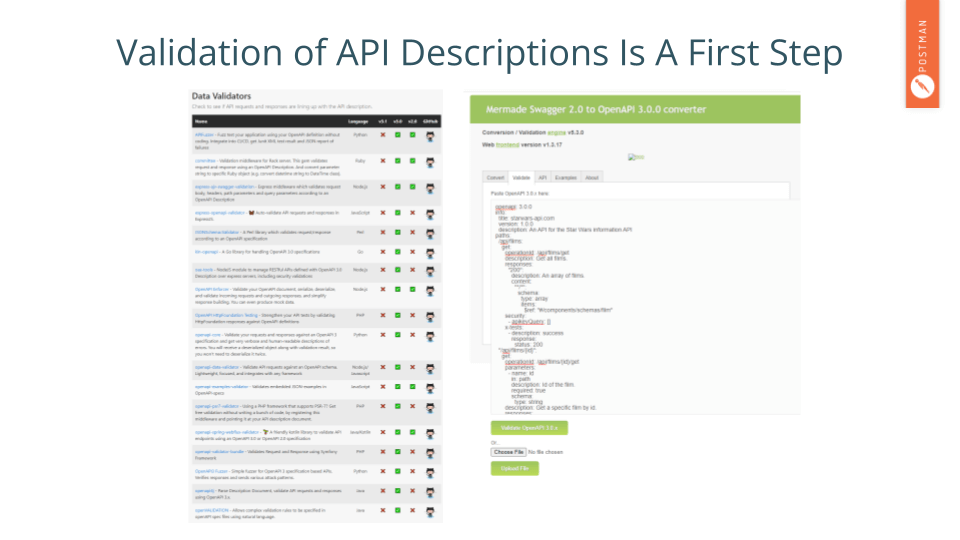
Similarly, several tools can parse an API description and nudge practice to a healthier place. Using tools in this way is a much healthier practice than manual reviews, where suddenly it is a contest of will over who is right.
There are a ton of API validators. OpenAPI.tools, the picture on the left, does a fantastic job of categorizing many of them.
Likewise, the OpenAPI Converter can also take an API description in a variety of formats. Both can be used to ensure an API description adherence to expectations, thus avoiding fragmentation.
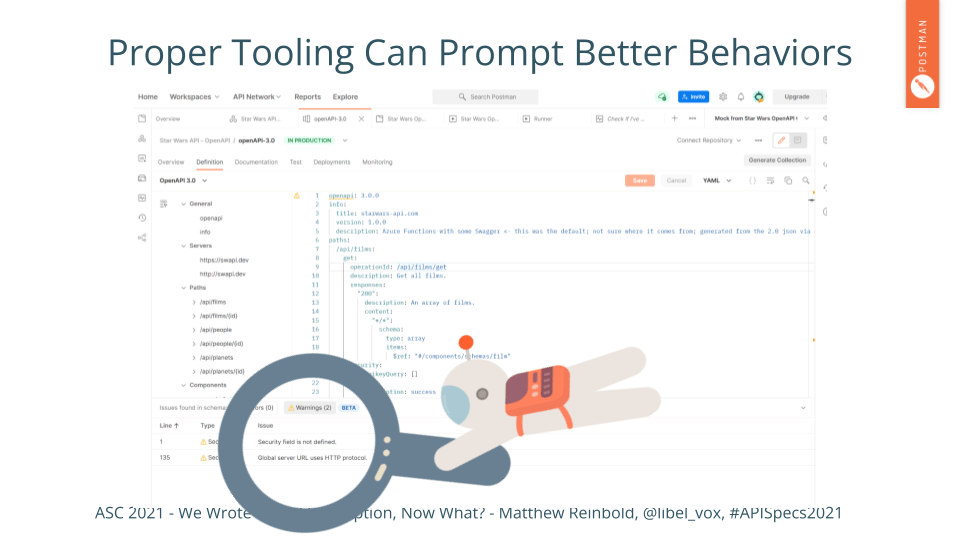
Security is a pressing issue at the moment. As I’m showing here in the slide, the tool is warning the API author that not only are they not providing any authorization for these endpoints, but the entirety of communication is happening over unsecured HTTP.
We’ll continue to see tooling get more opinionated. Thus better supporting API designers with insights when it is most beneficial - while they are designing.

That was a quick run through four areas - code gen, testing, monitoring, and governance that can benefit today from a description-centric approach. But let’s go even further. What happens when entire industries can sing from the same songbook?

I love this story that Jean Yang, founder and CEO of Akita software, shared recently.
The goal of Akita software was to help developers make sense of their complex distributed systems. They began to approach the problem in a systems way and briefly considered integration with open telemetry or maybe integrate with a service mesh like Envoy. The problem was that there had been no standardization; not everybody uses a service mesh, and when they do, it isn’t always Envoy!
Akita realized that APIs provided a standardized point that was uniformly consistent across all providers, architectures, and languages. Because services had adopted this common lingua franca, they were able to build a new set of observations and insights.

Likewise, a company called Stedi is doing some fantastic things.
EDI, or Electronic Data Interchange, has been around since the 1970s. It attempts to standardize the exchange of business information, like purchase orders and invoices.
Stedi applies modern approaches to schema validation, like JSON schema, to EDI. In the process, a whole suite of modern tooling can be leveraged for working with legacy formats; unlocking new value and opportunities in the process.

In conclusion, back to this guy - back to Guido.
In the centuries since Guido invented standardized musical notation, there were many additions. First there was duration. Then barlines, stylized clefs, dynamic markings, ties, and slurs were added. These changes supported a growing number of instruments and vocal styles.
Music grew beyond liturgical chants. The Renaissance era, where music tended to remain on a single tempo for the duration of the piece, gave way to the Baroque period, one marked by increased composition creativity. Baroque also established the opera, concerto, and sonata as musical genres.
This expansion didn’t happen in isolation. It is no coincidence that this creativity occurred when people had a greater ability to capture and share their intent. The development of a standardized notation, a specification, allowed composers to cross-pollinate, enrich, and evolve each others’ work.

But unless you’re a music nerd, that may be trivia. Let’s make this less abstract.
To help students remember his new standard, Guido also invented something else you might be familiar with; a mnemonic that helps people remember the steps between tones on his staff. You probably know it: do-re-mi.
That mnemonic is featured prominently in the 1965 film Sound of Music. That film, and the von Trapp children within, was seen by millions - including my wife and me.
I don’t have a Gretl, but I have a Greta. I also have a Liesel. Guido, in 1000 AD, wouldn’t know what a movie was, let alone comprehend his influence on it. Furthermore, he couldn’t conceive how a standard representation would ultimately influence my daughters’ names. But it did.
Swagger, the predecessor of the OpenAPI specification, came out in 2010, a little more than a decade ago! It’s not even a teenager yet!
Emergence from complex systems is an unpredictable thing. Our APIs ecosystems are complex systems. Who knows what future will emerge from the API descriptions that we create and share today? Whatever it is, I can’t wait to see what’s next.

Thank you so much for your time. If you want to get ahold of me, you can go to my website. You can also check out my email newsletter, and I’m pretty responsive on Twitter.

Thanks again!


