

Previously, I shared my team’s 2017 blueprint for API Governance. A component was measuring API quality using a “management tool” called Net Promoter Score, or NPS. While NPS is usually used to quantify customer loyalty, I had hoped to repurpose it. As I explained in my previous work, NPS shortcutted much of the hand-wringing and tedious defense of any methodology we derived ourselves; when measuring “quality of experience”, NPS was already lingua franca among leadership.
You are probably familiar with NPS, even if you don’t know it by name. Ever been asked to rank your experience between a 0 and 10? Most likely your answer is being compiled into an NPS score.
After a year of experimenting with NPS, however, we’ve moved on. This is a update on the why, what we’ve done in the first half of 2018, and where I see continuing challenges in measuring API quality.
There are many repudiations of NPS. However, none encapsulated as many of the problems we were experiencing as Jared Spool’s “Net Promoter Score Considered Harmful (and What UX Professionals Can Do About It)”.
Problems with NPS
It Skews Negative
As Jared points out, NPS is not a mean/average of all the scores collected. Rather, values “0-6” are considered detractors, or people who are unlikely to recommend something to others. Based on how my team used it, this was whether my API team would recommend the API design for emulation by others within the org. A “7” or “8” is passable; neither so offensive that we have a clear call to action, but not the best of what we hope to see. Anything rated “9” or “10” we shout about from the roof tops.
Framing scores int his way doesn’t match with people’s expectations. A ‘middle of the pack’ rating of 5 seems as though it should be neutral, neither good or bad, halfway between either pole. Yet, when computing NPS (the % of promoter scores minus the % of detractors), this value negatively impacts the rating.
It became a training issue for reviewers. And if it was non-obvious for the people doing the scoring, it certainly was a challenge for the development teams reviewed (who are different than executive leadership).
When meeting with busy folks outside your normal sphere of influence, you only get a few, fleeting minutes to hook them with “an ask”. Arguing over methodology minutia was not a good use of precious time.
Quality Improvement, on Individual APIs or Otherwise, is Washed Out
Let’s suppose a team has done the bare minimum for an API and, for various reasons, it exhibits intention that is neither consistent or cohesive with what has come before. My team would give this design a low score in an effort to incentivize improvement. Let’s say that score is “1” (a detractor). There’s no promoters, so the NPS results in a value of -100, or the worst score a design can get.
Shocked by “-100”, the group sets out to improve the design: perhaps they improve the documentation, address some of the unintuitive RPC patterns, etc. The prioritize this work against a backlog of competing features, resubmit for review, the reviewer acknowledges their effort by scoring them a “6” and…
…the team still gets -100 NPS. The team has made huge strides; their design is now above average! Yet, in the number reported to leadership, that effort was invisible. Imagine how demoralizing that would be on the part of the team, and how unlikely they’ll prioritize effort on new work in the future.
There’s also a scenario, as Jared points out, where a team improves a design previously rated “8”. That “neutral” score results in an NPS of 0. But, with a bit of polish, the design is re-reviewed at “9”. The result is an NPS of 100: a perfect score!
What is more valuable for future integrations? A team that improves a design from “1” to “6”, or a team that moves from “8” to a “9”? With NPS, the former is ignored. In the latter, it is overemphasized.
The purpose of that my team produces these metrics is to incentivize positive behavior. If the correct behavior is happening, but it isn’t reflected in the metrics, then we need to change things.
What We’re Doing Now
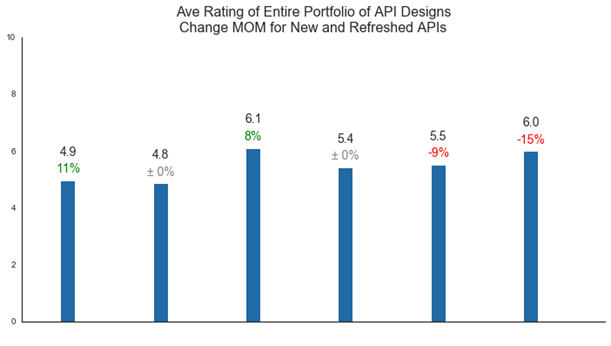
Since moving away from NPS, we’ve gone to a much more straightforward average of reviewer scores. While each of these have a high degree of nuance, at a high level APIs are scored on:
- Standards Adherence
- Completeness of the Documentation
- Consistency and Cohesion with Previously Published Work
- Viability to Exist as an API Product
The average score remains useful for leadership to know where they are in their API design maturity. But what is much more actionable for teams is directed feedback. A team that learns that their design averaged a score of “6” could cast about for changes to make on their next version. Or they could address a detailed list of concerns.
What’s Next
Stop Converting Noise into Science
After moving away from computing NPS, we still had a considerable amount of scoring activity that was useful. But it was based on the 11-point (0-10) scale used by NPS. So, when we continued with more straightforward averages, we maintained the previous scale so that we could blend the old and new scores.
Unfortunately, I’d be hard pressed to define the specific difference between an API design where one is rated a “4” and another is rated “5” on an 11-point scale. The distinction isn’t clear and leads to situations where one person’s “7” may be another person’s “5”.
A 3-point scale is very straightforward: if an API design is “bad”, give it a “1”, just ok APIs get a “2”, and awesome API designs get a “3”. However, that doesn’t leave a whole lot of nuance. Something akin to a 5-point scale seems to be a better fit. However, retrofitting the past year of scoring activity, along with avoiding polarization tendencies remains a challenge.
Conflicts of Interest when Judge, Jury, and Executioner
Presenting a picture of where leadership is at in their journey is one thing. We create the expectations and measure how well we meet those expectations. A conflict of interest arises when leadership, subsequently, sets specific scoring targets that they expect my reviewing team, working with software development teams, to deliver.
That could be a problem. The USDA food inspector isn’t required to show improvement in the produce they’re reviewing. The engineers that inspect bridges aren’t expected to have their defects detected trend downward overtime. Putting those who review a thing with a well intentioned, but misplaced, incentive can result in some troubling outcomes. There’s tremendous pressure to pull a punch here, or turn a blind eye there.
The team and I need to define a better way forward here, with clear accountability and laser focus on driving the correct outcomes.
Conclusions
Ultimately, this is part of a healthy process. We tried something, learned a ton in the process, and are iterating to get to something better. We have a ways to go. But I think it’s a sign of maturity to be able to take on new information and evolve to something better because of it.
Do you have an API quality metrics story? Are you wrestling with accountability and socialization of organizational improvements? Shoot me a line. I’d love to compare notes.


